


An Introduction To Data Quality Checks For Data Engineers
Attempting to merge data engineers with data quality...TypeError: unsupported operand type(s) for +: 'data engineer' and 'data quality'

Hey there!👋 It’s Elias - back with another blog this time on data quality. It’s been a recent theme for me and something we ought to talk about more. How are you dealing with data quality?
Why is it that data quality is always left for last or never given the attention?
There are many reasons one can think of:
Business priorities to get products out there fast
Lack of defined business rules for the data
Uncertainty on how to implement data quality checks
Culture of an organisation to let things break and be fixed
Data engineering still feels like its in that that awkward adolescent phase, with best practices slowly becoming more embedded with the rise (and decline?) of the modern data stack.
But when it comes to data quality and testing, it's like that kid from primary school who was always picked last in PE.

Data quality checks are essential but at the same time, overdoing it can also backfire. There can be a lot to think about and depending on the data pipeline, the implementation method will vary.
You need to think about what types of checks you need and how it will fit into your data pipeline.
Will adding data quality checkpoints at each step of the pipeline be optimal, or will there be redundant tests as a result of many data manipulation steps?
Depending on the amount of data you need to check, what are the costs associated?
There will be a tradeoff between the quality of your output data and the cost to manage and run the checks.
Types of Data Quality Checks
The main types of data quality checks are
Row
Column
Data type
Syntactic
Freshness
Consistency
Validity
Of all the types of data quality checks, the most common and fundamental ones are row counts. For example, counting the total amount of rows, repeated rows or missing rows.
When it comes to fact tables, you can usually expect a steady row count over time, so suddenly seeing 4x the row count in your data pipeline output should raise alarms about some possible faulty joins.
Up next are column checks - for example, counting the number of null values in a certain column or if a column is missing.
Open source libraries like Great Expectations provide frameworks to implement these expectations with threshold settings you can define to allow for acceptable error - i.e. if you expect 95% of your rows for a certain column to have non-null values - more on how this can be setup below.
Data type checking is another one that Pythonista’s know all too well that can be a right pain. As data is pushed between scripts and read into Pandas dataframes, data types can change.
Ensuring columns are of a specific type avoids unexpected TypeErrors and is a good way to catch breaking changes when intermediate pipeline stages are modified or you’re when pulling data from a third party source that could change the order of the columns.
Syntactic checks validate the data is in the correct format, which relates closely to data type checks as you would expect date columns to be in a certain format based on whether it is a string or a datetime type column.
Depending on the type of data and how often it changes, you could also check for the freshness of the data to ensure the source has not changed since extraction as well as consistency checks across sources or targets.
Validity checks ensure that the data is accurate and conforms to a set of business rules. For example, if a column must contain only UK phone numbers, it can validate via an expectation of having a certain prefix or number of integers.
Data Quality Checking Frameworks
There are a handful of open source libraries out there that provide a framework around which you can build data quality checks:
Great Expectations
Pandera
Deequ
DBT
Pydantic
In this blog I’m going to focus on Great Expectations (GX) as I have used it extensively in past projects and is the one I am most familiar with.
I recommend checking out the official documentation that covers all the ways that it can be implemented. Here I’ll only be going over some of the ways I have used it to save you some reading time!
One of the nice things about GX is the ability to use it ‘out of the box’ with a simple pip install and with a few lines of code you can run expectations against your pandas dataframes.
Let’s see how this works with an example dataframe, with expectations to perform simple row counts and column checks.
With GX installed, we can then define our expectations - here is a list of example checks on row counts and columns that we know will pass.
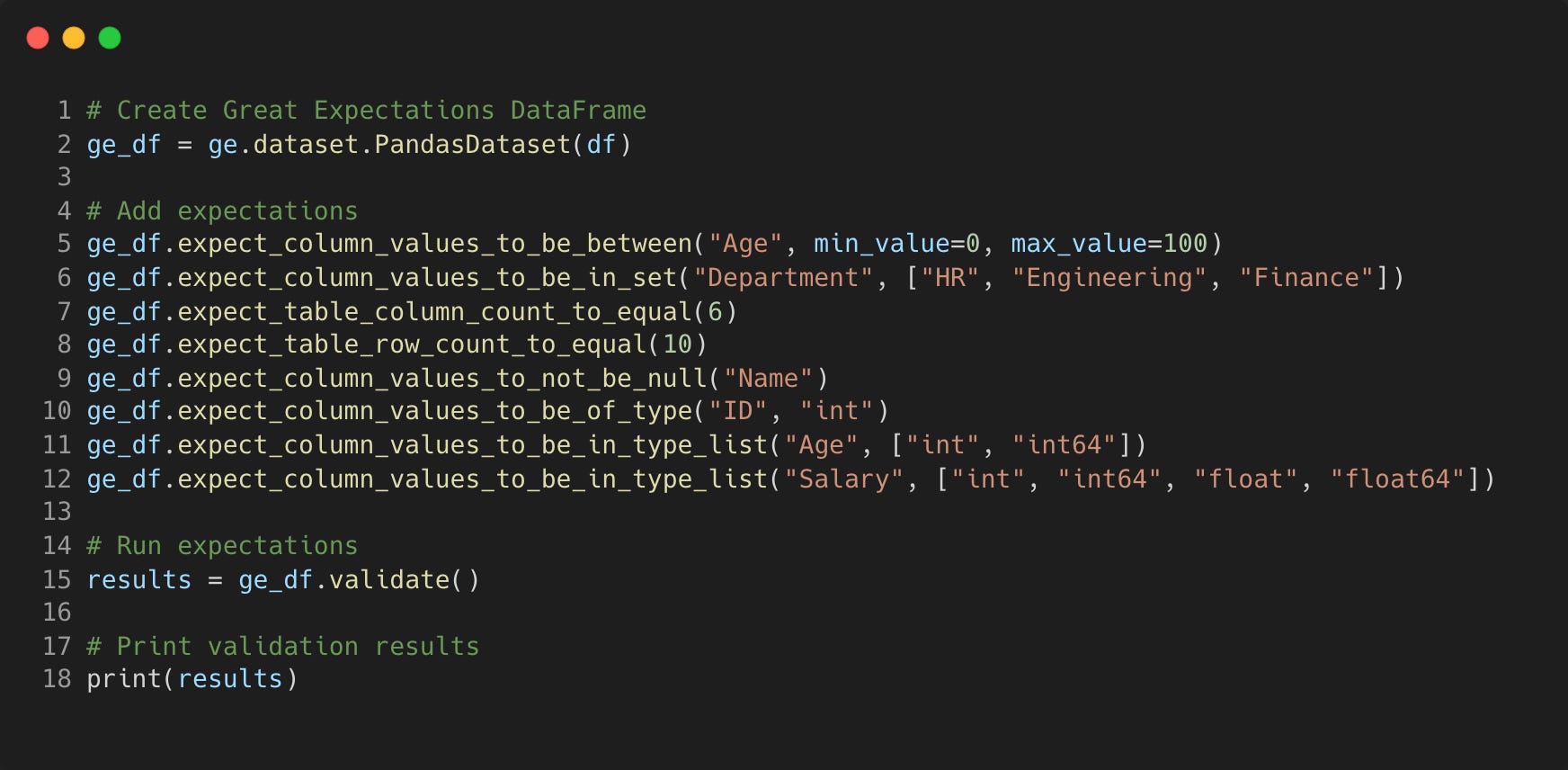
When we run this code, we get a JSON output of the expectations results (cropped to the first one)
If we deliberately put a check that we know will fail, the message will look like this instead

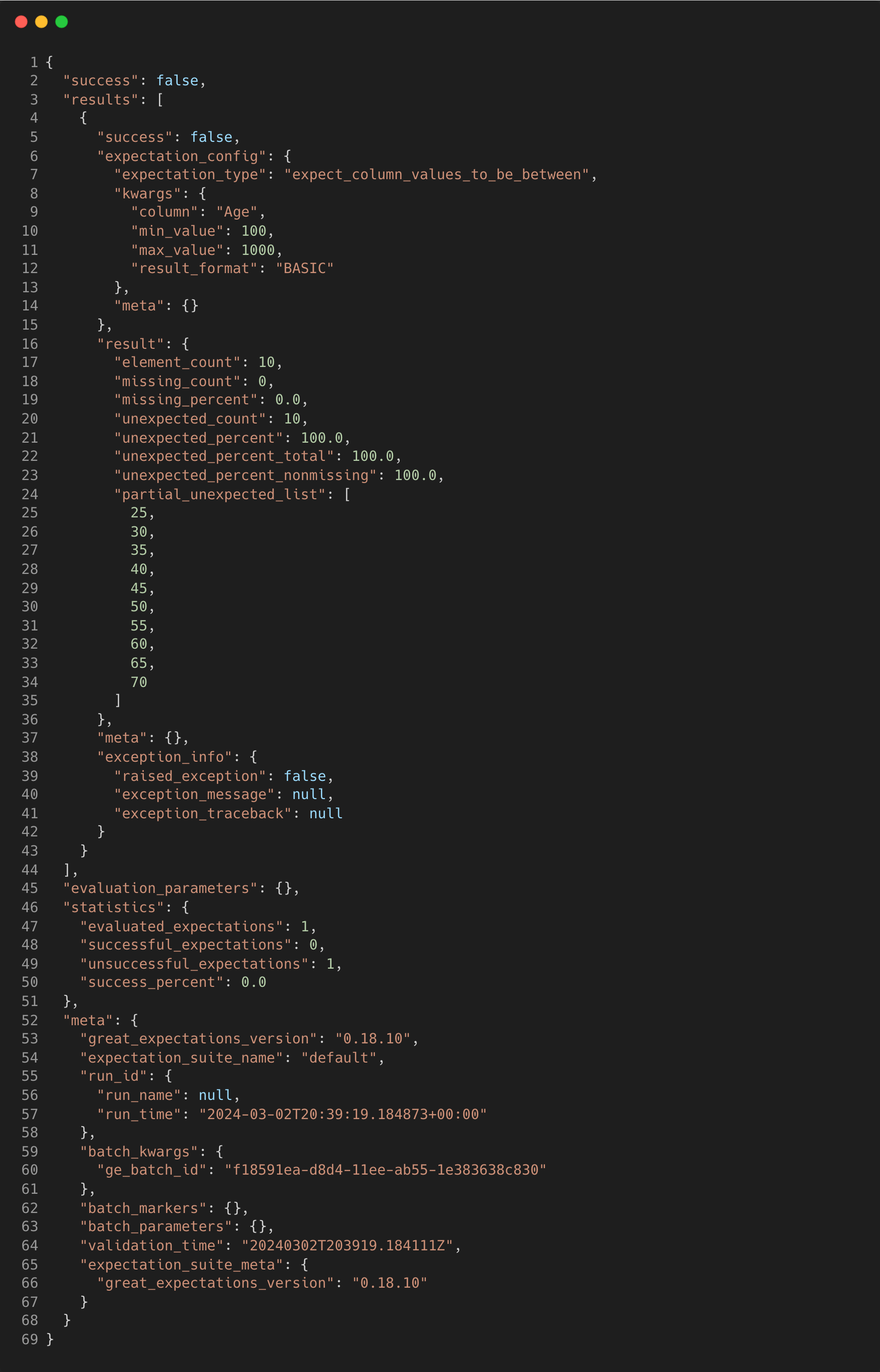
Here we can appreciate the full contents of the message as it details the number of instances that the expectation failed for.
This is a simplistic implementation of using the Pandas API to check out data. GX also provides a comprehensive framework where you can define your data context, connect your source data, create expectations suites and run them against your data.
Depending on how your data pipeline is setup, you might want such a fully-fledged solution to run checkpoints throughout each stage of a pipeline, or just a lightweight one to run data checks on in-memory data.
Sometimes GX might not be the best solution for you - If you’re already a DBT user, then utilising the data quality checking framework provided by DBT is probably a no-brainer.
Some may also not like the complexity that can arise with the configuration required.
One issue I came across with colleagues on a work project was implementing the simple Pandas API data checking solution within an AWS Lambda function.
This would work by triggering the lambda on S3 event notifications as files were dropped in the bucket. However, the large amount of dependencies that are installed with GX like jupyter notebooks makes the package too large for use in Lambda code or layers.
To get around this, you would have to use either S3 to store the packages so you can pull them down and pip install them on every invocation, use Elastic File Storage mounted on an EC2 or use a container image as they allow up to 10GB compared to the standard 250MB Lambda limitation!
Closing Thoughts
Data engineers need to care about data quality. Automated processes should be in place to identify when there is a drift in your data or when there is something unexpected. Otherwise, how can we produce reliable data that people can make decisions from?