


Configuration Data Formats in Data Engineering
Configuration files control how things behave, where data may go, and what transformations occur. Yet, the choice of format for these files is often not fully thought through.

When I started out, I didn’t give much thought to how I stored my configurations. A JSON file here, a YAML file there, whatever came to my mind first. As projects grew more complex, the way I structured my configuration files began to matter a lot more.
A good configuration format can make a pipeline easier to maintain, debug and scale. Whether a developer or a non technical person will need to view or edit the configuration file may influence the choice of format. It’s worth taking a step back to think about the different options available and what they bring to the table.
In this post, I’ll walk you through some of the most popular data formats used for configuration files in config-driven data pipelines and other use cases.

Config Driven Data Pipelines
A config-driven data pipeline is a data processing system where the behaviour of the pipeline is controlled by configuration files, rather than being hardcoded in the code.
You can define things like data sources, transformations, and destinations through external configuration, making it easier to manage the pipeline.
You can think of this simply as an abstraction of an if-else statement. The approach allows for flexibility and maintainability as you can tweak the pipeline’s behaviour without changing the code.
It can often be a topic of contention though - whether the complexity is merely moved rather than removed and if the steep learning curve is worth it. I'll leave that to you to decide, and if you're interested in exploring the topic further, check out Daniel Beach's hot take on config-driven data pipelines.
Overview of Data Format Options
We'll look at the following most common formats in data engineering:
JSON 🛠️ Simple, widely used, and easy to integrate with many tools.
YAML 📜 Human readable, great for complex configurations.
TOML ✨ Minimal, clear and included in the standard Python library
INI 📝 Simple but limited in structure, often used with Pytest
XML 🏋️♂️ Highly structured and self-descriptive, though verbose
Why is YAML So Common?
YAML often ends up as the go-to format for configuration files. Its rise in popularity mirrors the shift in data engineering towards more abstraction and a declarative style.
DevOps relies on YAML for declarative setups, allowing developers to specify infrastructure, CI/CD pipelines, and application configurations.
YAML is just as easy to parse as JSON, but it offers greater flexibility, especially when it comes to maintainability and readability.
The lack of brackets and quotes makes it easier to type, and the ability to add comments makes it much more user-friendly when collaborating. JSON began with the ability to add comments, but was later removed to prevent developers from using them to specify parser directives, which complicated it.
YAML’s Powerful Features in Action
One of the features I find particularly useful in YAML, especially in contexts like GitLab CI/CD, is the use of anchors and reference tags. Anchors let you reference constant values across multiple places in a single file, which is a huge win for keeping your configurations DRY (Don’t Repeat Yourself).
Another handy feature is the << syntax, which allows you to inject entire lists of parameters in a single line, streamlining complex configurations.
For example, consider deploying a Python project via a GitLab CI/CD YAMl script that requires Poetry for Python dependency management. As a seasoned data engineer, you store the commands required to install Poetry in a template file named poetry-setup.yml which you include and reference in all your jobs.
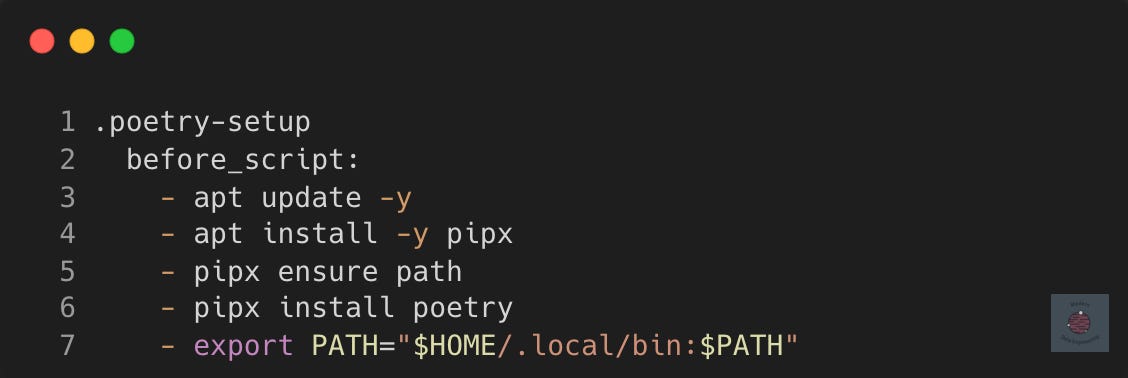
The template file defines a
before_scriptthat installs Poetry with pipx and sets the path. This will need to be ran on any job which requires any Poetry commands.
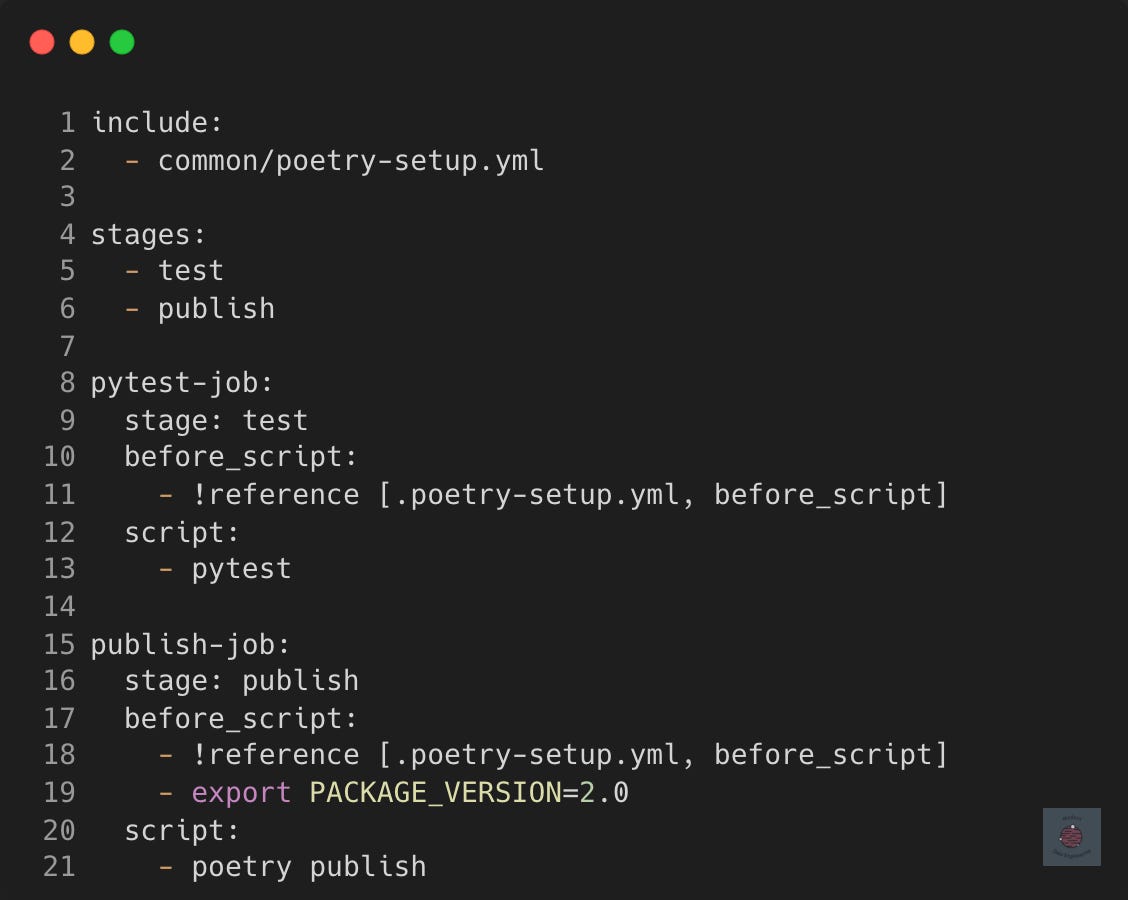
In the example deployment script, we include the file common/poetry-setup.yml and use the !reference tag to select the before_script for re-use in each job.
Any additional steps to run in the before_script can be added without having to worry about it being overwritten, which would be the case if a default before_script was defined in the script instead.
More Features, More Complexity
YAML isn’t without its drawbacks. While JSON has remained relatively stable since its introduction in 2001, YAML has undergone multiple versions, and different implementations have slight variations.
The richness also adds complexity, and that can lead to headaches when you can't tell where the extra whitespace is causing you issues.
One quirky thing about YAML I came across while reading The yaml document from hell is how it handles numbers. For example, if you enter a number below 60, YAML might interpret it as a sexagesimal (base 60) value.
Clarity in JSON vs. YAML
When it comes to clarity, JSON is a clear win. It’s immediately obvious whether you’re working with a map, a list, or a string.
With YAML, I often find myself second-guessing whether I’ve got the indentation or hyphens right, and I sometimes convert YAML to JSON just to double-check my work.
Having said that, JSON has a strict aversion to trailing commas. Forgetting to remove that last comma is an easy way to run into linting errors when your AWS IAM policies suddenly won’t apply.
INI - The Old Reliable
INI files are as old-school as it gets. The format is simple: key-value pairs grouped into sections, with a bit of whitespace and maybe a few comments thrown in.
Simplicity comes at a cost here. INI files are great for basic configurations, but they fall apart when things get more complex. There’s no support for nested structures, and you can’t really do much in terms of data types beyond strings and numbers.
A common use of INI files is for configuring Pytest. Before I started using Poetry for my Python projects, I would configure my Pytest with something like this
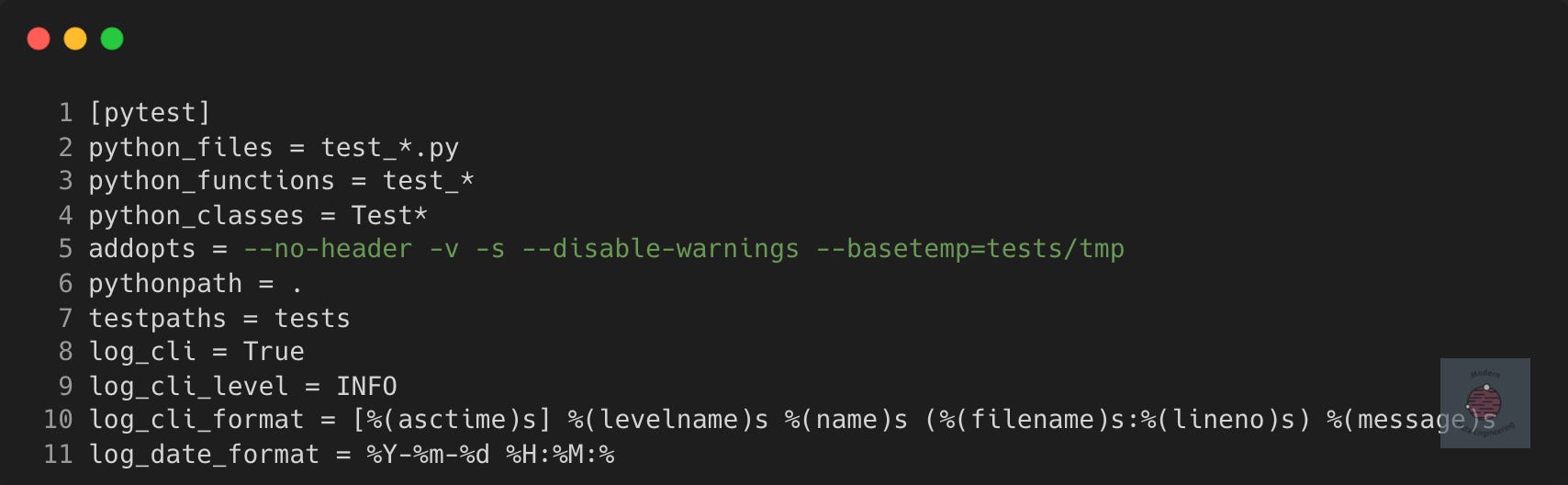
Often we'll need lists and nested data, say for a config-driven data pipeline, which rules out flat INI formats for complex workflows.
TOML: The Minimalist’s Choice
TOML is like the new kid on the block, but one that’s already wise beyond its years. The basic building blocks of a TOML file are tables and key-value pairs. The syntax is straightforward, almost like a hybrid of INI’s simplicity and YAML’s structure. It has the JSON data model, but a syntax that allows comments.
It’s also a huge plus that TOML is included in the standard Python library, so you don’t have to install external dependencies just to parse a config file.
What I really appreciate about TOML is how it strikes a balance between readability and structure. Unlike in YAML, in TOML strings are always quoted, so you don't have values that look like strings but aren't.
Tables in TOML are like sections in an INI file. They start with a name enclosed in square brackets and everything under this table header is part of that table until a new table or subsection starts.
You'll have probably seen its use in the pyproject.toml files that holds Python project configurations. For example
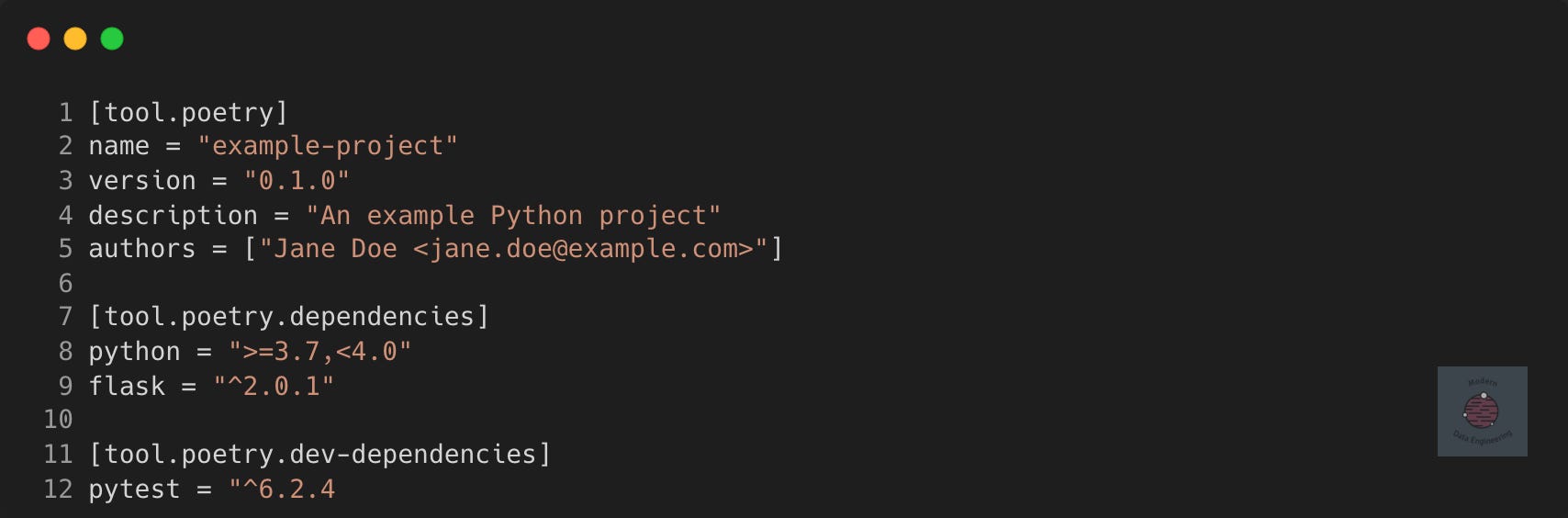
Dot notation in TOML allows you to define nested tables more succinctly. The dependencies table is a nested part of the tool.poetry table. The dot notation just allows a more compact way to define where each key-value pair belongs.
I think TOML is a solid choice for simple config-driven data pipelines if simplicity and readability are top priorities. This is especially true if other non-technical users may need to view or edit the configuration file.
The minimalism also means it’s not as powerful as YAML. If you need to do complex nesting or reference other parts of the file, TOML might not be the right tool for the job.
TOML vs StrictYAML
TOML is analogous to the StrictYAML project. A type-safe YAML parser focused on secure parsing, strict validation, and preserving readability. StrictYAML, by contrast, was designed for use cases where there may be many files per project with more complex hierarchies, a use case where TOML starts to show problems.
TOML’s Hidden Complexity
The dot structure is easy for parsers to read but not as intuitive for humans to understand. As a result, many TOML users end up adding non-meaningful indentation, similar to how we use indentation in JSON to make the hierarchy clearer.
This approach works, but it feels like a workaround rather than a solution, especially when compared to Python’s meaningful indentation, which directly reflects the structure without the need for extra markers.
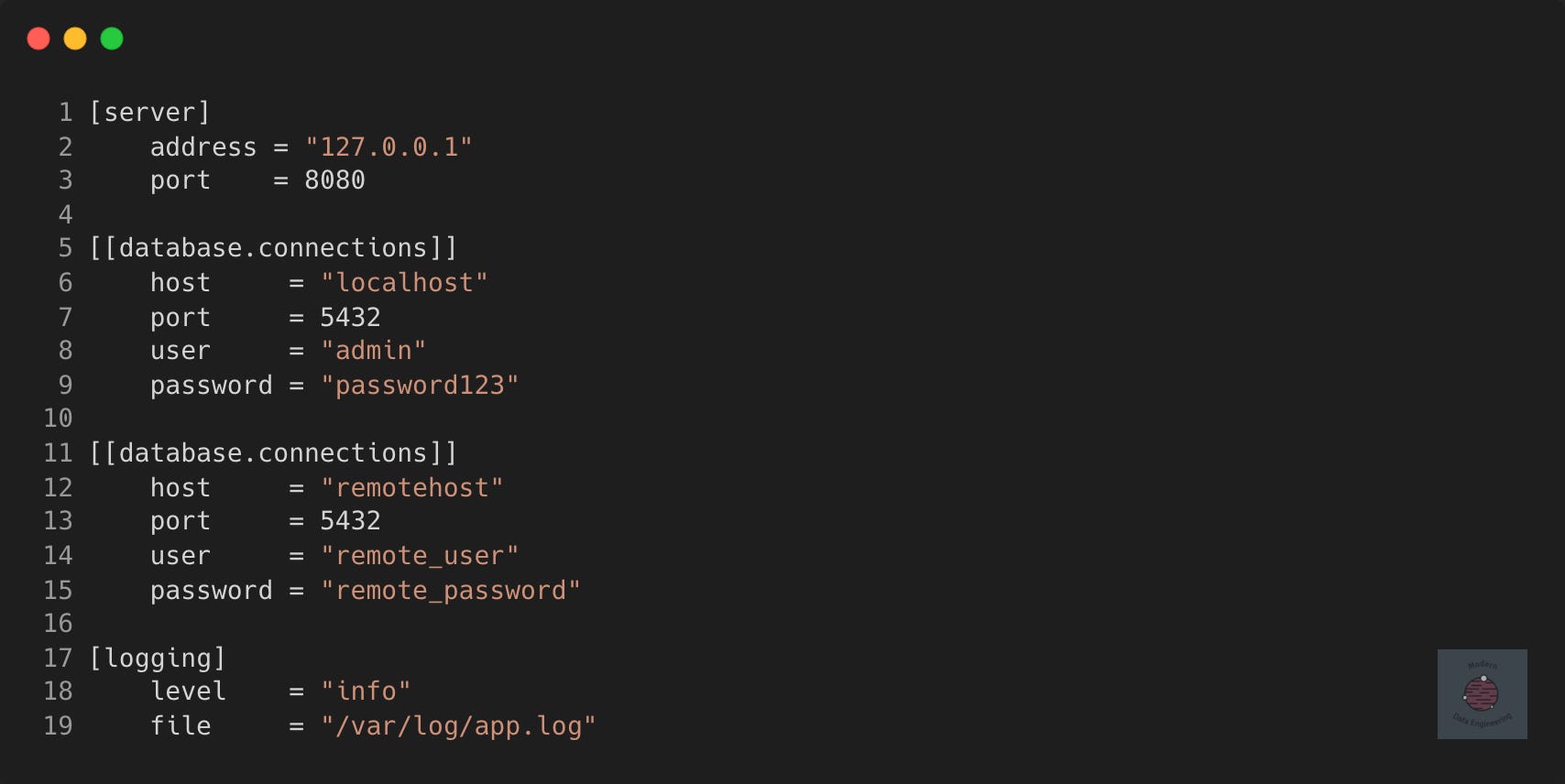
TOML’s Date and Time Pitfalls
Another area where TOML complicates things is with its built-in date and time parsing. Dates and times are notoriously tricky to handle due to numerous edge cases and unexpected complications. By including this feature, TOML introduces complexity that could have been avoided.
JSON and StrictYAML take a different approach by decoupling this complexity. Instead of trying to parse dates and times within the format itself, they leave it to specialised tools that are better suited for the job.
XML - The Heavyweight
Finally, the notorious XML. XML is the heavyweight champion of structured data formats. It’s been around for decades and is incredibly powerful. Every piece of data is wrapped in tags, making it easy to understand what each element represents. This level of detail is great when you’re dealing with complex data that needs to be both human-readable and machine-readable.
But XML’s strength is also its weakness. All those tags add up, making XML verbose and often hard to read. I’ve spent more time than I care to admit trying to figure out where one tag ends and another begins, especially in large files.
It can be overkill for simple configurations, but remains a necessity when you’re dealing with systems that have standardised on XML, such as software development configuration and in financial transaction and messaging.
I've personally tried converting all my Apple Health XML data into dataframes for a mini project and it was not a walk in the park. If you’re feeling adventurous, I’ll let you experience the intricacies of XML for yourself.
Good one.
I have heavily used yaml for files and json for dynamo configs.