


Event-Driven Data Pipelines in AWS - Part 1
Data engineers should always be architecting

In my early days as an analyst, I was always eager to automate tasks, often finding myself repeating lines of code without scalable solutions in sight. As I delved deeper into the field of data engineering, I started tinkering with cloud, where I found myself hooked on the possibilities.
With hours spent poring over documentation and experimenting on various projects, I began to appreciate the art of architecting solutions. It became clear to me that understanding the limitations of different implementations was crucial to crafting effective solutions.

I realised that architecture is not just a technical skill but also a form of leadership. It demands a blend of technical competence and practical experience to make informed decisions about implementation strategies. It’s based on a deep understanding of constraints, data characteristics, and available technology. It's about selecting the right tools to construct robust and scalable systems.
A well-architected solution should not only meet business needs but also maintain high standards. Being able to identify potential issues, bottlenecks, and weigh trade-offs is essential.
Key Architectural Styles
Keeping the list minimal, these are some of the most commonly used architectural styles, each offering their own set of advantages and disadvantages.
Monolithic
Microservices
Event-Driven
Serverless
For example, monolithic structures offer simplicity and cost-effectiveness but can become cumbersome as applications grow. Microservices provide great scalability by breaking down the application into independent components. Serverless computing offers rapid development and scalability without the hassle of managing infrastructure.
When it comes to responsiveness and adaptability, event-driven design works well as it enables real-time reactions through loosely coupled systems. Components of the system communicate by producing and consuming events, enabling asynchronous interactions.
Event-driven designs provide:
Easy Scaling: As your data needs grow, event-based systems can handle the load by scaling horizontally.
Flexible Setup: Things change fast in data work - you can adapt quickly with less hassle.
Less Tied Up: Events keep components loosely connected so they don't need to know too much about each other, which makes things simpler to manage.
Real-Time Action: Sometimes, you need data processed right away. Event-driven systems react to events as they come in.
Event-Driven Design Patterns
A basic design pattern used in event driven solutions in a serverless architecture could involve triggering a Lambda function via S3 Event Notifications. Every new object-created event would initiate a Lambda function to process the data.

Notifications are designed to be delivered at least once - but delivery is not guaranteed (interesting read that has since updated with latest changes to AWS documentation) and the order may vary. It works well for small scale applications, but lacks fallback methods when too many requests come through. This can cause throttling of the Lambda function and result in some messages not being processed.
Another limitation with using S3 Event Notifications directly with Lambda functions is that for each bucket, S3 events are limited to a single destination i.e. only one Lambda function. This means to trigger multiple different Lambda functions for parallel processing on the same data, you are required to have extra event notifications pointing to different S3 prefixes.
Queued processing with SQS
One way in which we can improve the fault tolerance would be to include an SQS queue between the Lambda function and the S3 event. It is useful when ordering is critical, provides guaranteed delivery and event re-driving capabilities. This makes it more resilient to traffic spikes and can tolerate high throughput.
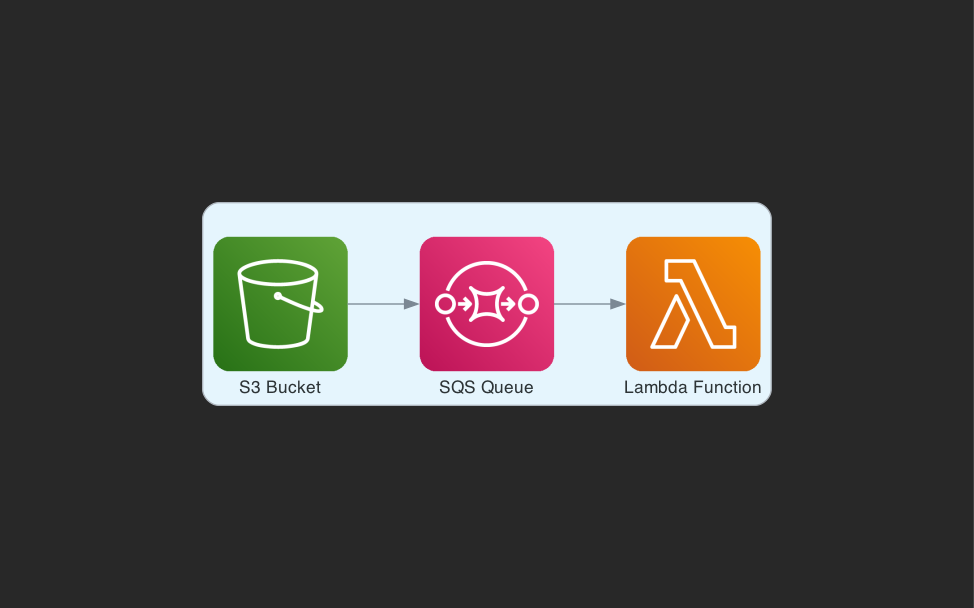
There are certain limitations and strategies to overcome when working with SQS:
Throttling and Sequential Processing: SQS helps prevent Lambda function overload by processing messages sequentially, ensuring that the system can handle high throughput without risking failures due to overload.
Batching: Messages are processed in batches and this can be configured depending on message size and the number of lambda functions to be run simultaneously.
Handling Failed Messages: If a message fails during processing, SQS provides options for handling these failures. For example, a Dead-Letter Queue (DLQ), where failed messages are redirected for later analysis and potential reprocessing.
Cost Considerations: SQS can reduce Lambda invocation costs by processing multiple messages in a batch, but it's this should be weighed against the additional cost of publishing messages to SQS and the polling requests made by the Lambda service.
Retries All Messages: If a message in a batch fails and causes an exception, all messages will be retried once they become visible in the queue again, meaning messages may be processed multiple times. You can configure the event source mapping to allow partial batch responses to prevent reprocessing messages by only making the failed messages visible after the visibility timeout. You can read more about the details of this on the AWS documentation here
Fan-out processing with SNS
Fan-out is a popular design pattern that makes use of a single event bus in your application, where all the messages posted into it are automatically sent to all of your services.
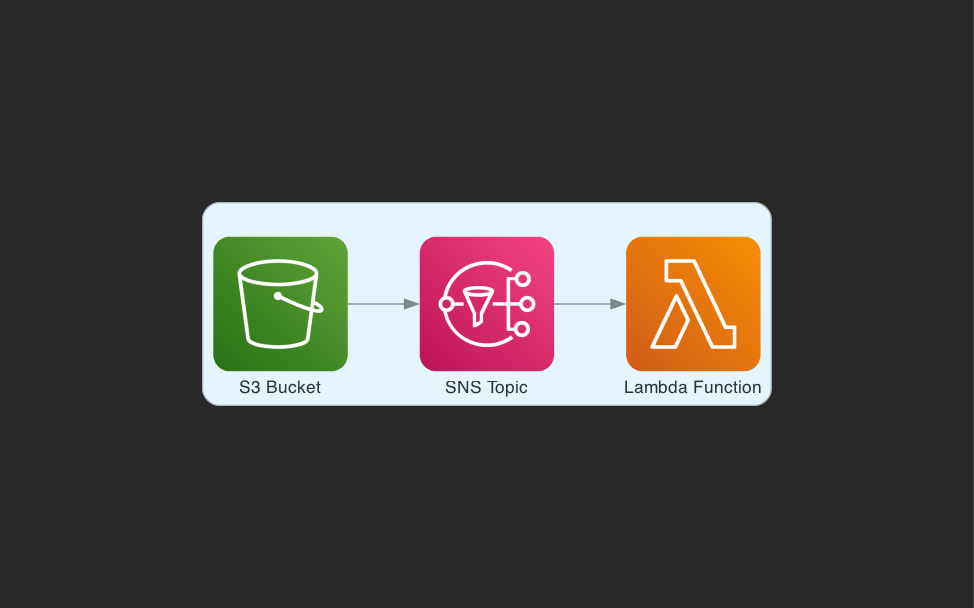
If you need to fan-out S3 Event Notifications to multiple Lambda functions, adding SNS instead is a more flexible option. This uses a publish-subscribe method whereby the events are published to a topic and the Lambda functions are subscribed to the topics.
In fact, when using SNS for asynchronous invocation, the Lambda service behind the scenes uses internal SQS queues to invoke the functions. This Youtube video by AWS Events deep dives into the workings of Lambda if you’re interested in learning more about it.
Why use SNS?
Native DLQ Support: SNS provides built-in support for DLQs, enabling the redirection of failed messages to a designated DLQ for further analysis and processing.
Retry Mechanisms: SNS utilises internal SQS queues and retry mechanisms to handle invocation retries. Specifically, SNS pollers will retry invoking the associated Lambda function up to three times before considering it a failed invocation, before the message is redirected to the DLQ or another specified destination.
Cost Considerations: SNS topics will be an extra cost factor.
Concurrency Control: The retry mechanism employed by SNS, coupled with Lambda's reserved concurrency setting, provides a form of concurrency control. This helps manage the rate of message processing and ensures that the system can handle fluctuations in message throughput without overwhelming downstream resources.
Compared to DLQ’s, Lambda Destination provides more useful capabilities by adding additional function execution information as it captures both the error and the failed event, while DLQs only capture the failed event. So you don't need to spend time searching for error logs related to failed messages in SQS DLQ, making error resolution quicker.
It’s also possible to combine the two so that queues subscribe to SNS topics, allowing for flexible message distribution and parallel consumption by Lambda functions or any other target service.
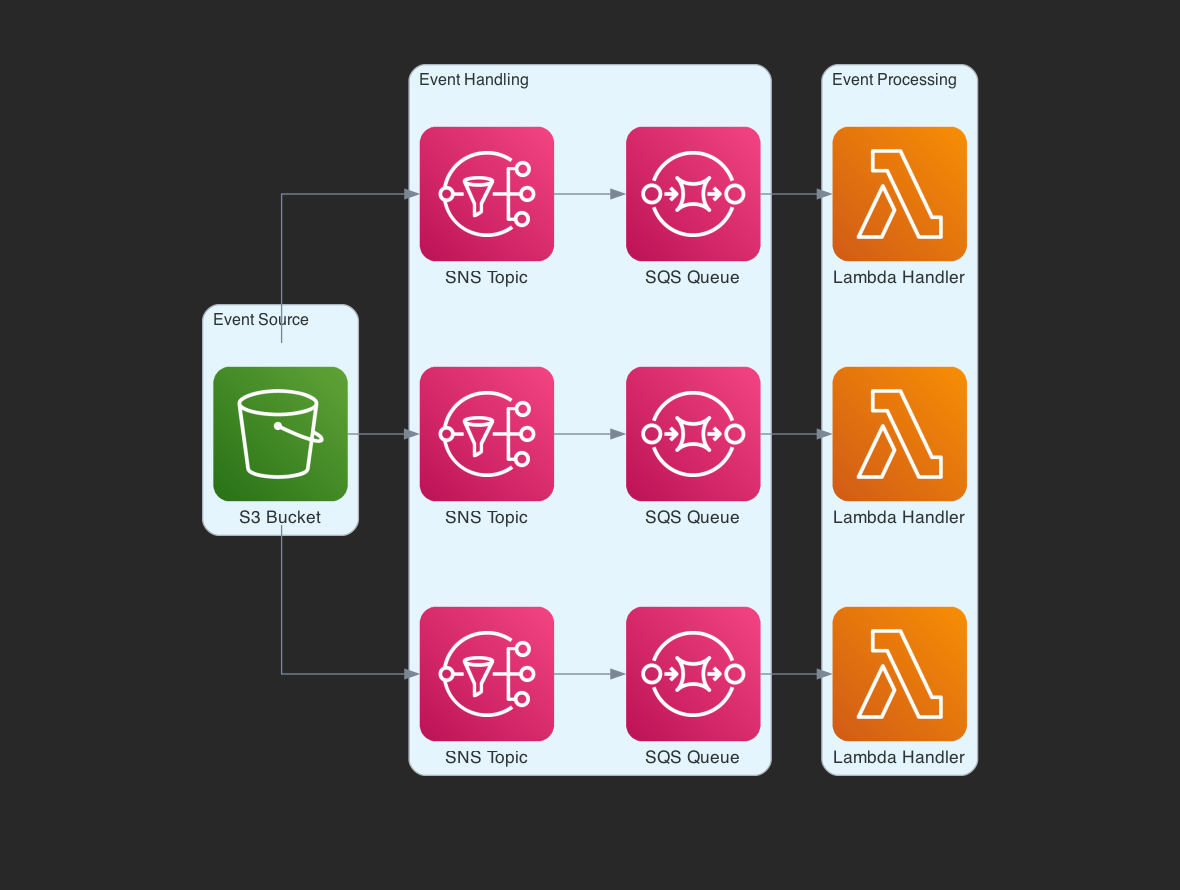
This makes best use of decoupling, fanout pattern and observability while providing resilience and adaptability in event-driven architectures. In part 2 we’ll look at how to implement event driven systems using Terraform.
Sounds familiar to one of my article but on gcp.