


First Impressions of Mage
Will Mage replace Airflow?


Mage is not just any ordinary data orchestration tool, it could be the superhero of modern data engineering. It streamlines and optimises data processing in an effortless way and will make your other data pipeline tools look like rusty old relics.
I started using Mage several months ago for personal projects and I was pleasantly surprised by how much I enjoyed it. As an avid user of Airflow, I appreciated the challenges and learning experiences that came with it. This would include handling the different components, choosing the the appropriate executor and setting up a database. I also liked writing minimalistic DAGs with the TaskFlow API. Was Mage going to be as interesting?
For some, the simplicity that comes with Mage is what will be favoured, while others may be disappointed with the feeling that it resembles a low code tool. While you definitely still need to code your own pipeline logic, there are many built-in integrations and templated blocks that will actually save you time from needing to implement your own.
If you haven’t heard of Mage yet, I recommend Andreas Kertz’s livestream with the CEO of Mage Tommy Dang. The demo covered some of the core functionality of Mage
Building a data integration pipeline
Exploring data within the tool
Testing and validating data
Pipeline scheduling and monitoring
What does Mage do particularly well?
Setting Up
There are a few things that stand out with Mage. Firstly, the ease in setting up Mage locally is where it beats Airflow for most data engineers. Mage offers a quick way to build pipelines by running it with pip, conda, or Docker. The platform is designed to provide an easy developer experience, as evidenced by the single command needed to launch a development environment. Many more developers will be able to get hands-on faster without the need for managing the infrastructure. Seasoned developers can also leverage their terraform modules to self-host an environment with their preferred cloud provider.
Templates
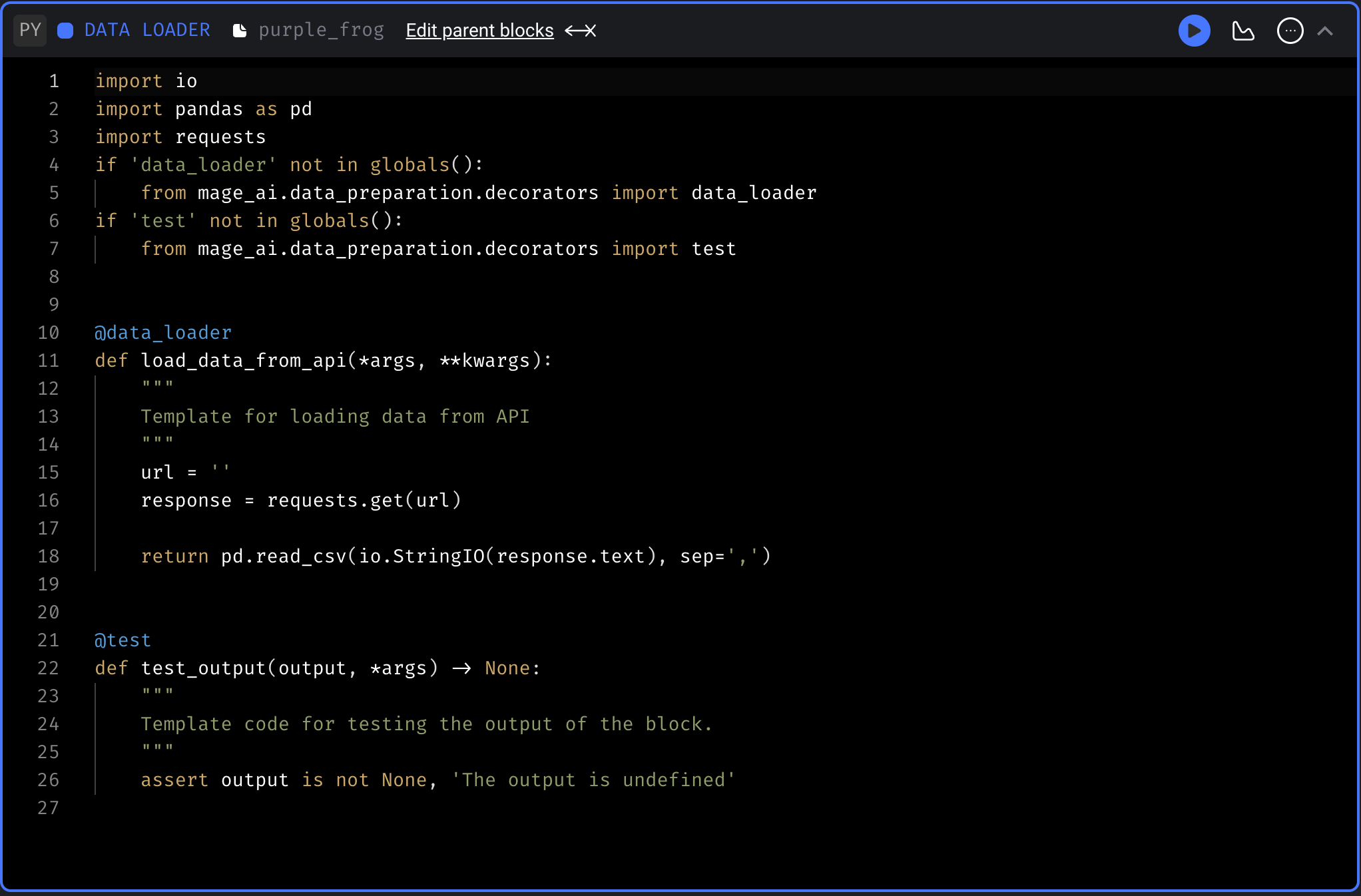
Mage makes following engineering best practises second nature by embracing modularity in the design, with each step in the pipeline being a file with code that can be reused and tested. Pipelines are made up of code blocks, of which there are multiple types:
Data Loader
Data Exporter
Sensor
Transformer
Custom
Callback
You can use Python, SQL or R code in any block file, allowing for flexibility within the pipeline. For example, you could use a Data Loader block with the Python API template to extract data, then a Transformer block to make the data into a dataframe of your desired shape. Finally, a Data Exporter block to export it to a target database. Callback blocks hold functions that trigger based on a linked pipeline block succeeding or failing, which simplifies handling errors and triggering notifications.
Data First
With orchestration tools like Airflow comes the tendency to pass around volumes of data between tasks by writing to disk when no external cloud storage is being used. While XComs are suitable for small amounts of data, Airflow is not a data processing framework and so large data frames will cause memory issues.Mage enables data to flow between blocks seamlessly and uses parallel processing methods to optimise data processing.
In the example templated Python API Data Loader block above, you can make changes to your code and run it directly by pressing the play button in the top right hand corner for instant feedback on how your data looks. The chart button allows you to create different visuals as well as run some template data quality checks. These include checking a percentage of missing values, counting the number of unique values and generating summaries.
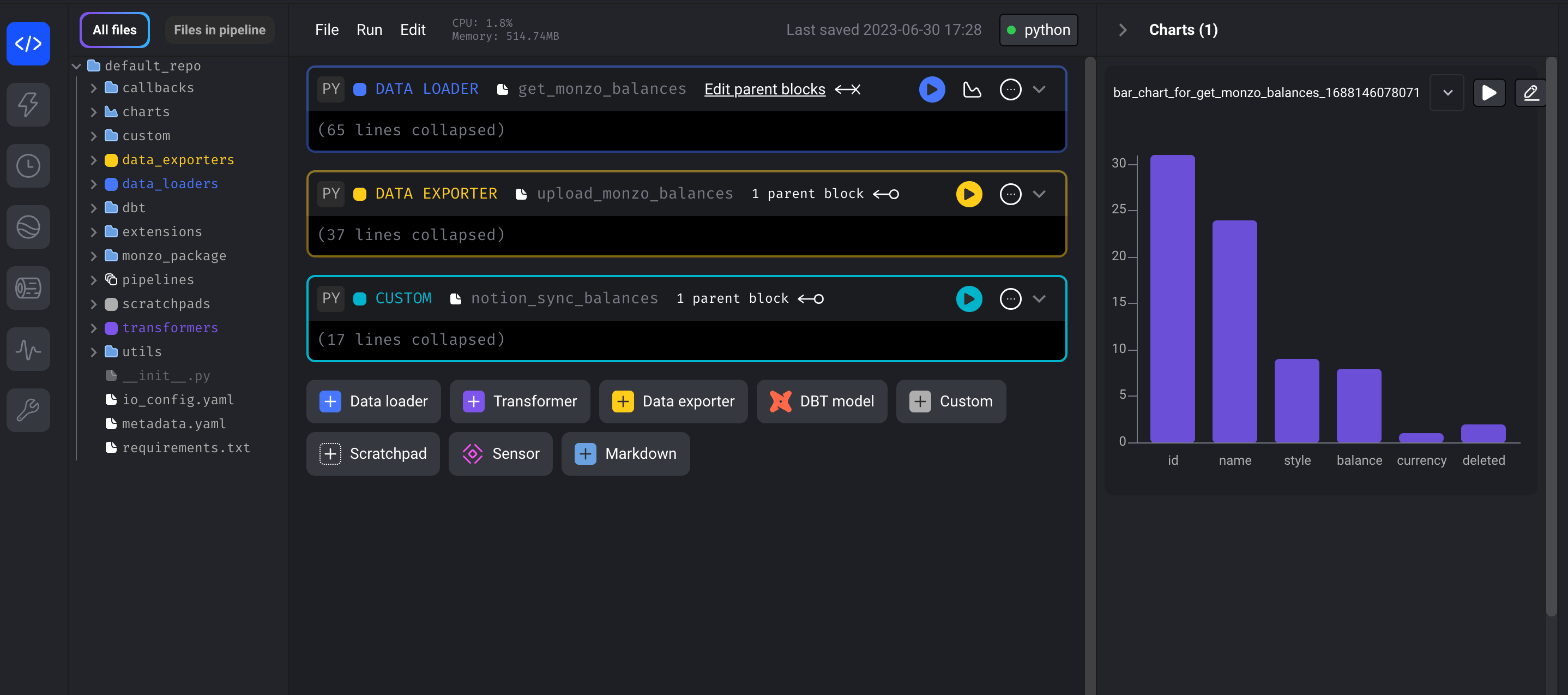
With data being core to the design philosophy, you can version each output of a code block so that it can be reused and you can track your data lineage with it’s built-in data catalogue. Mage also has a Power Ups feature, which currently allows you to integrate Great Expectations into your pipeline to perform data quality checks.
Tests
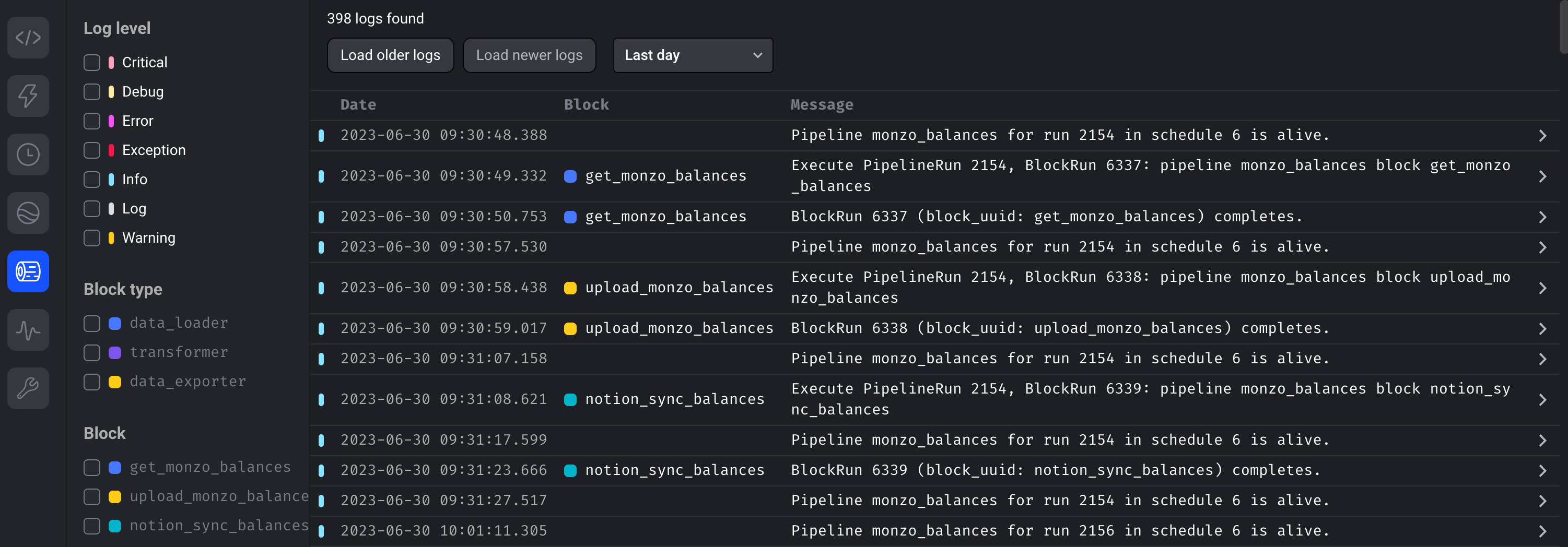
Mage improves the testability of data pipelines by integrating tests within each step of the pipeline. Templated test functions are included in each block to facilitate writing tests. This takes away the worry of varying dependencies in different environments, as is often encountered when running end-to-end DAG tests with Airflow.
Having tests for each block ensures that the code block performs the tasks on the input data as expected. Debugging failed tasks on Airflow is often cumbersome, requiring you to make changes to the codebase and re-running pipelines, especially if your setup didn’t allow for re-running of individual tasks. With Notebook style development in Mage and easy to read pipeline logs, debugging is simpler. Mage also has a simple retry mechanism that can automatically trigger, thanks to the modular design of Mage pipelines. No more repetitive changing of pipelines and re-running until the pipeline works!
Visuals
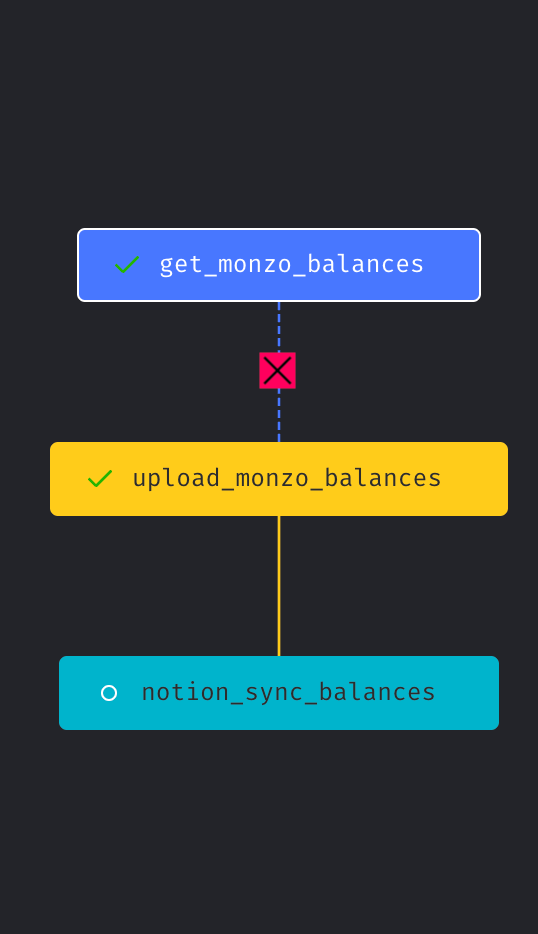
The creators of Mage have clearly put a large emphasis on making it user friendly and an attractive tool. The UI is less clunky than its competitors and it just looks good. The Tree view of the pipeline blocks makes it easy to see your pipeline come together and you can easily set dependencies by clicking and forming arrows. Being able to visualise your data with charts at each block brings your pipeline to life before it is even complete.
Closing Thoughts
The abundance of features and accessibility of Mage opens doors for many more data engineers to get their hands dirty. Removing the burden of managing the infrastructure and integrating features means many more data engineers from different functions can begin to create data pipelines with ease. From seamless data ingestion tools to responsive development and data validation - Mage has ticked nearly all the boxes.
I would still recommend data engineers eager to pick up a variety of skills to use Airflow first for the experience. But, if your focus is to build pipelines fast with a single tool, then Mage is great.
I’m quite excited to see how Mage will develop in the future given it’s a new player in the field, and i’ll be exploring how to create some streaming data pipelines with it in the near future!
Wow, this is an amazing article! Thank you so much for sharing!!!!
thanks for sharing!