


Event-Driven Data Pipelines in AWS - Part 2
An introduction to building AWS infrastructure with Terraform

In Part 1 we looked at event-driven design patterns for serverless architectures.
S3 Event Notifications for simple triggering of Lambda functions
Queue’s for processing high throughput with dead letter queues to handle failures
SNS topics for a fanout pattern where an event can trigger multiple services in parallel
We highlighted the importance of understanding architectural solutions as a data engineer, which requires a blend of technical expertise and practical experience. We then explored Event-driven design patterns as a means of enabling real-time reactions through loosely coupled systems, promoting responsiveness and adaptability. In this post we’ll look at how we can deploy these to AWS using Terraform.
Why Should Data Engineers Know Terraform?
A data engineer doesn't just code all day, they also design, plan, tinker, analyse, fix bugs, attend meetings and manage trade off of best principles all day. Being familiar with Terraform is a great skill to have to automate provisioning and management of infrastructure. As well as a cross-functional skill, it aligns data engineers with DevOps principles, fostering continuous integration, delivery, and deployment.
All the code will be available in GitHub as the screenshots may be cropped to only address the specific resources mentioned and avoid repeating lines.
Setup
To follow this example tutorial you will need:
You will need to use your AWS access key and secret access key to authenticate with the Terraform AWS provider. You can first set these as environment variables in your shell so you can later make Terraform commands.

Note that creating AWS resources can incur fees, so make sure to be on the free tier to avoid this!
Preparation
First let’s make a new directory to store your Terraform configuration for creating a Lambda function.

Within here we’ll create the Lambda function code and zip it up for the Lambda service to ingest.

Add the following sample Lambda function python code

Now you can zip this code up

To store our Terraform configuration, create a file named main.tf - this will hold your Terraform provider information and resource definitions and any environment variables you might create. In this example we can keep it all within this file, but as your configuration becomes more complex it makes sense to separate these into their own Terraform files, as stored in the examples on GitHub.

For this example we’ll need to create a Lambda function that uses a Python runtime and can take in a zip file. An associated role for the function will give it permissions to:
Create a log stream to send logs to CloudWatch
Allow it to GET, LIST and PUT objects into S3
Allow the Lambda to be invoked by any resource
Typically it’s best practice to give permissions to specific resources to keep it more locked down. Copy the following configuration and change the variables as you wish.
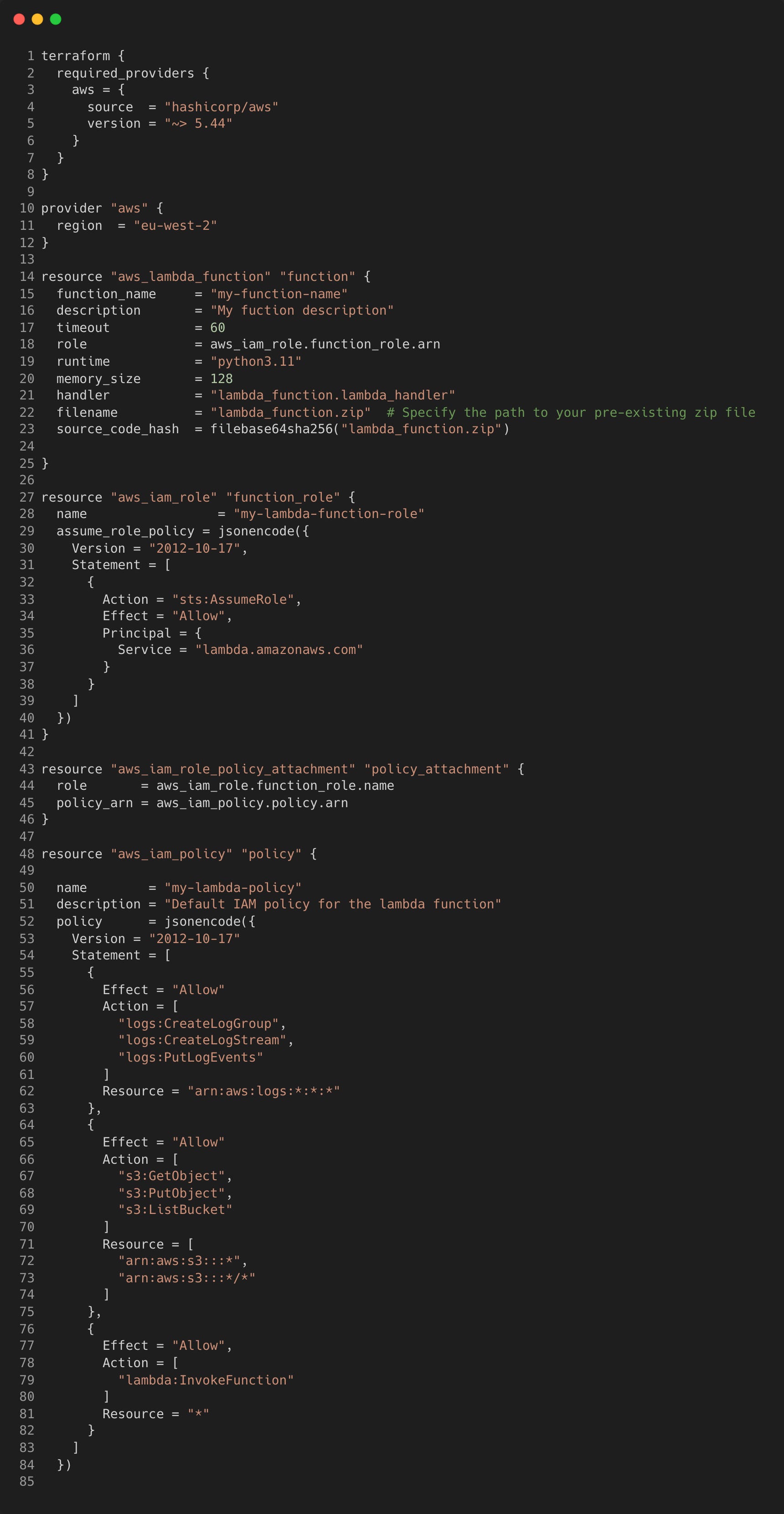
Quick breakdown of the different types of blocks here:
The
terraformblock in a configuration file sets Terraform operations and provider specifications. Each provider, defined inrequired_providers, specifies a source, likehashicorp/awsfor the AWS provider.providerblocks configure specific providers, facilitating resource management across multiple sources, enabling integration between providers.resourceblocks define infrastructure components, specifying type (e.g.,aws_lambda_function) and name (e.g.,function). Arguments within resource blocks configure components, such as Lambda runtime or memory size.
Initialisation
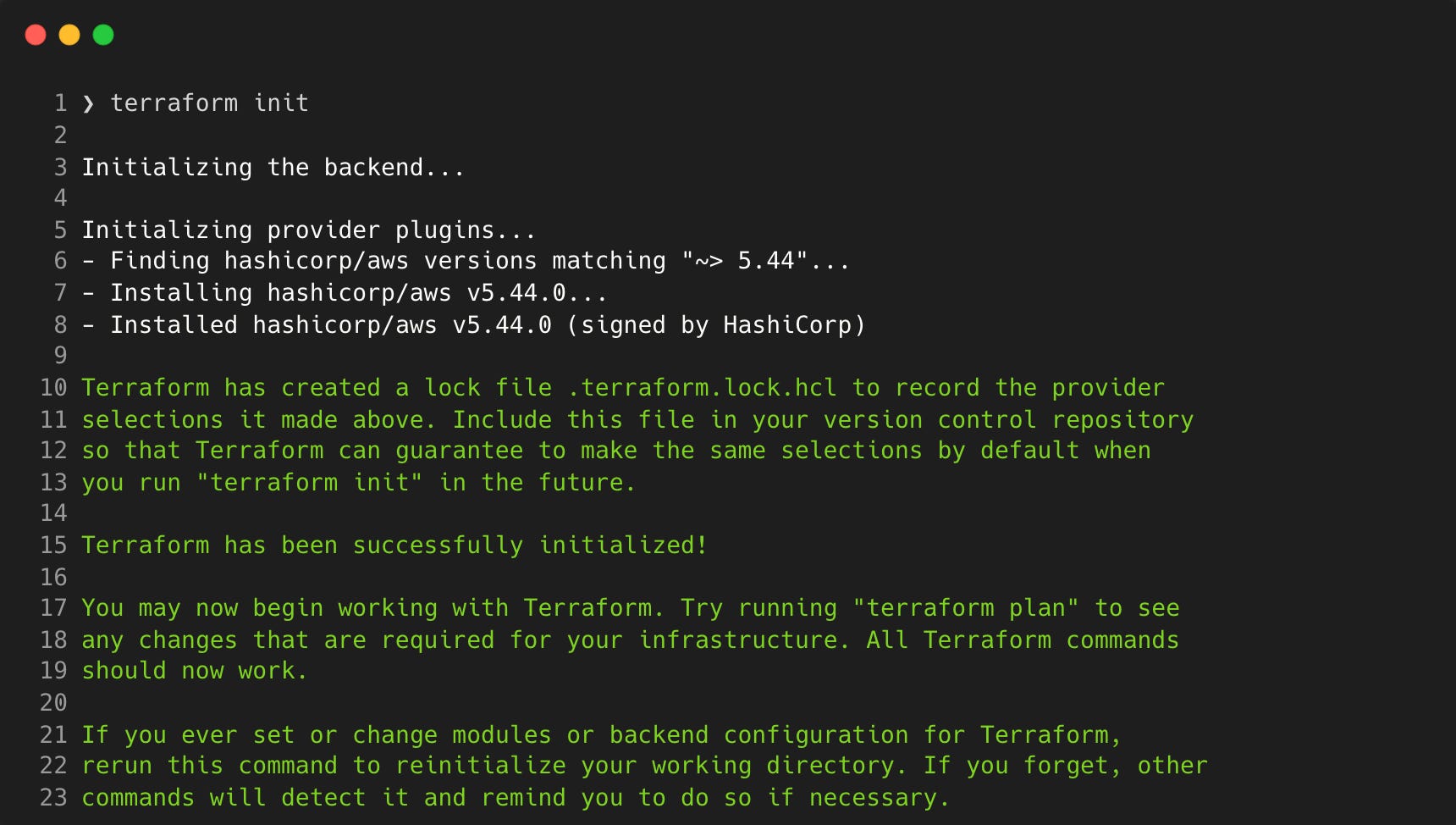
The first Terraform command you will need to run is terraform init to initialise the directory. This will download and install the AWS provider. It will also create a lock file in the directory that will specify the provider version used.
Creation
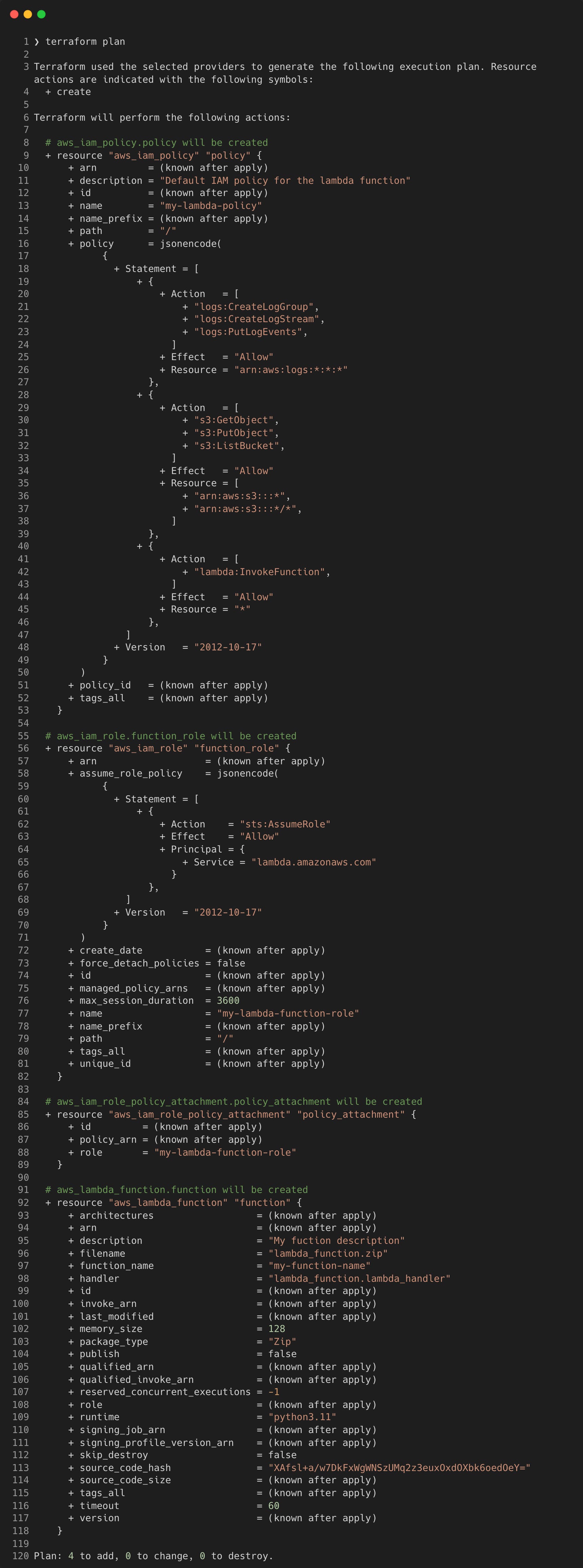
Now you’re ready to run terraform plan to view the execution plan which details what changes will occur when you run terraform apply.
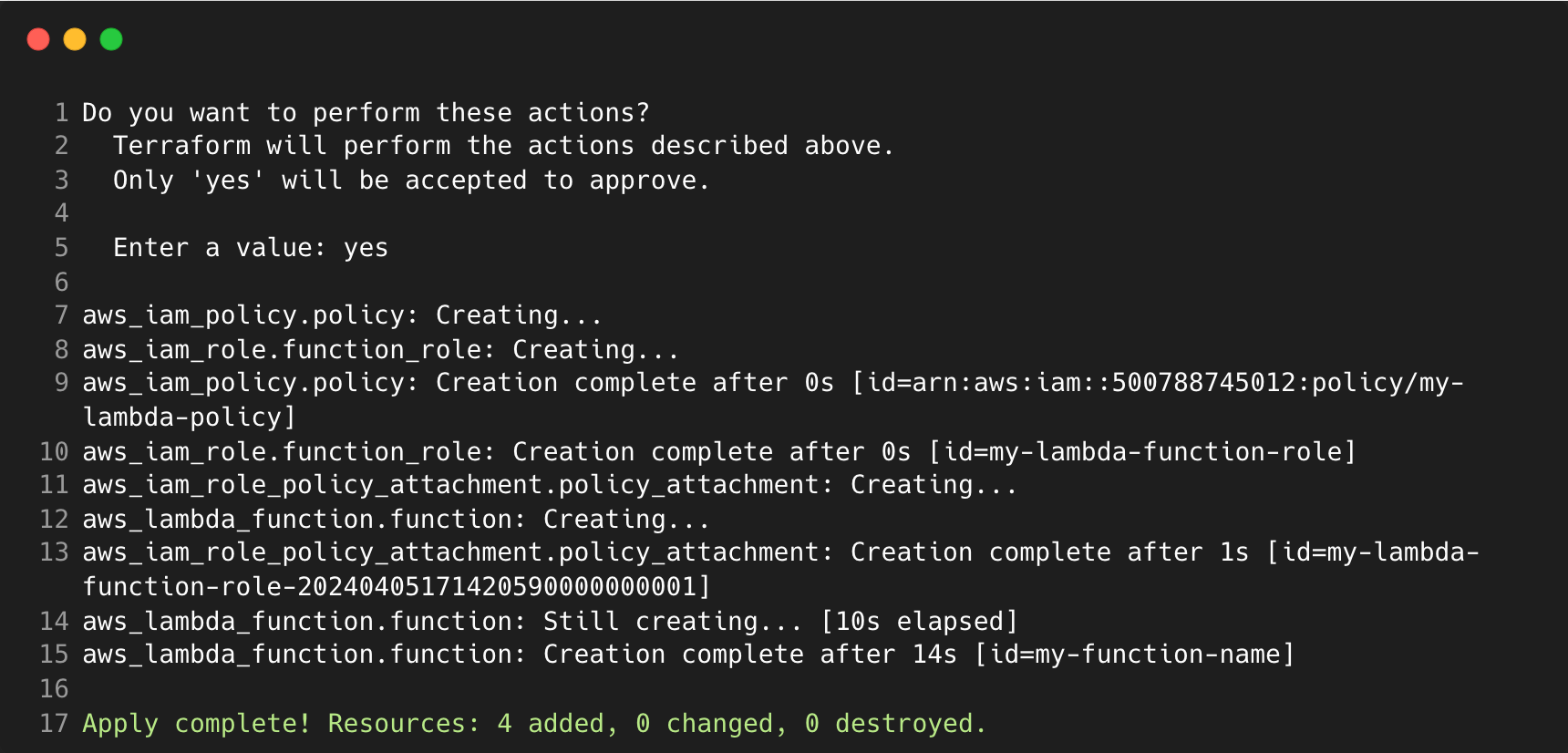
Running terraform apply, we can input ‘yes’ in response to the confirmation message and see that the infrastructure is being created. The apply command will also display the execution plan, but is not shown below to save space.
A terraform.tfstate file will have been generated in your directory - this holds the metadata related to the resources you created and is required for tracking further changes. Best practise is to store this in a secure location such as Amazon S3 as it can contain sensitive data and should not be written to version control.
Teardown
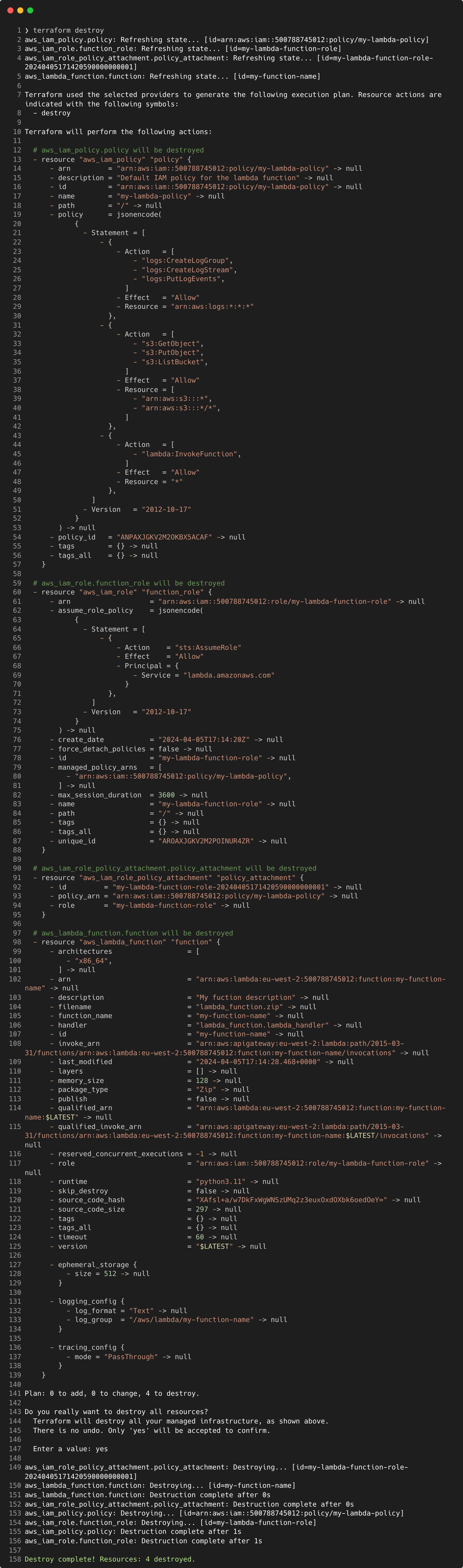
To tear down what was just created, we can run terraform destroy and it will undo all the changes made.
S3 Event Notifications, Queues and SNS
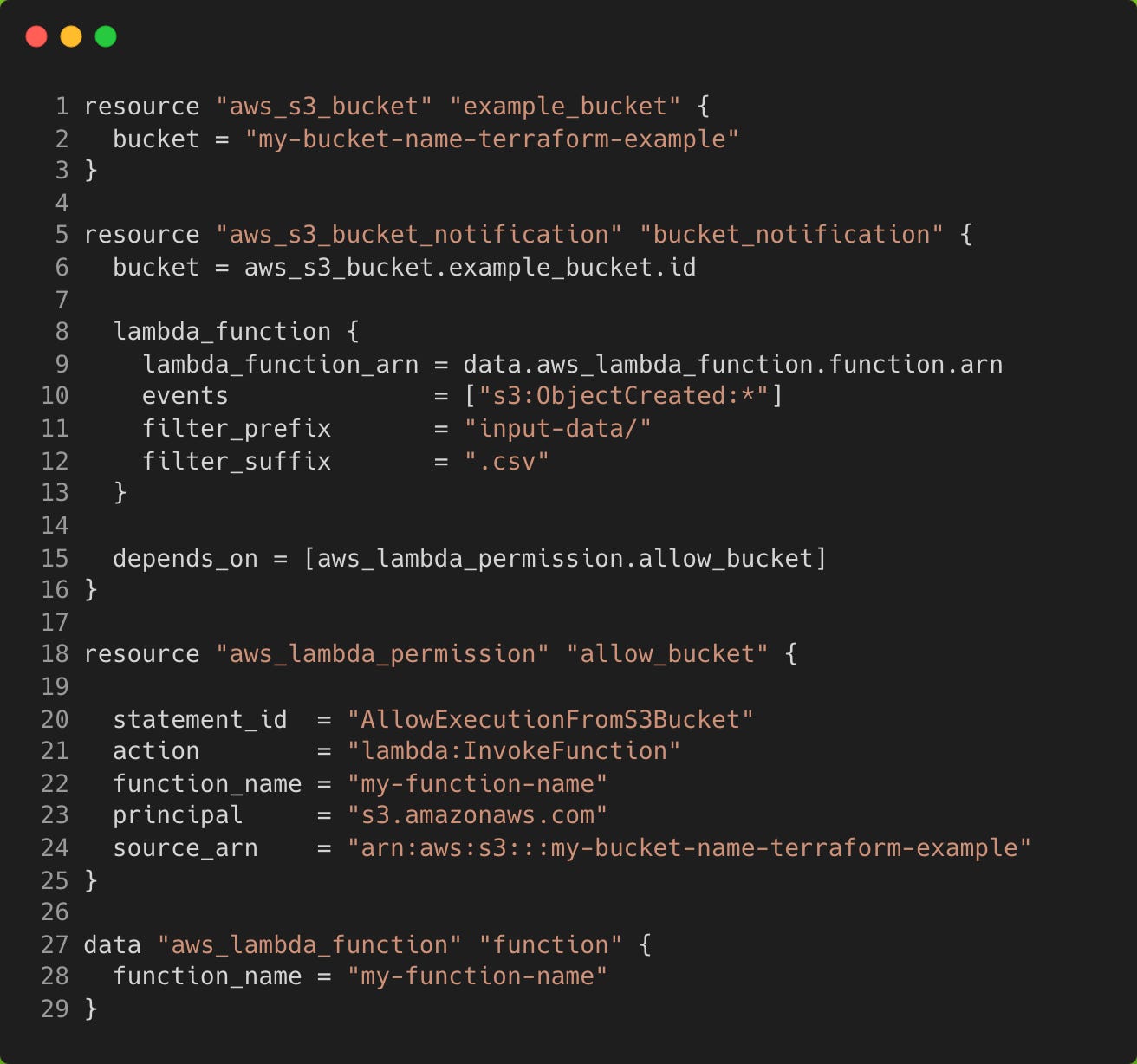
Now that we have the basics covered, let’s look at adding some extra resources. The first example from Part 1 describes an S3 Event Notification that can trigger a Lambda function. A simple use case might be to use a Lambda function to generate reports off of some input data that is dumped into an S3 bucket.
The event notification can be configured to trigger a Lambda function when a marker file is put into S3 that signals input data are available. We’ll assume this is placed in a folder named input-data/ and the file would have a suffix .csv.
Create a new directory in the same parent folder as terraform-lambda called terraform-lambda-s3 and create a new main.tf file. We can use a data source to get the ARN of our Lambda function that already exists, and we also need to permission the Lambda function to be triggered by the bucket.
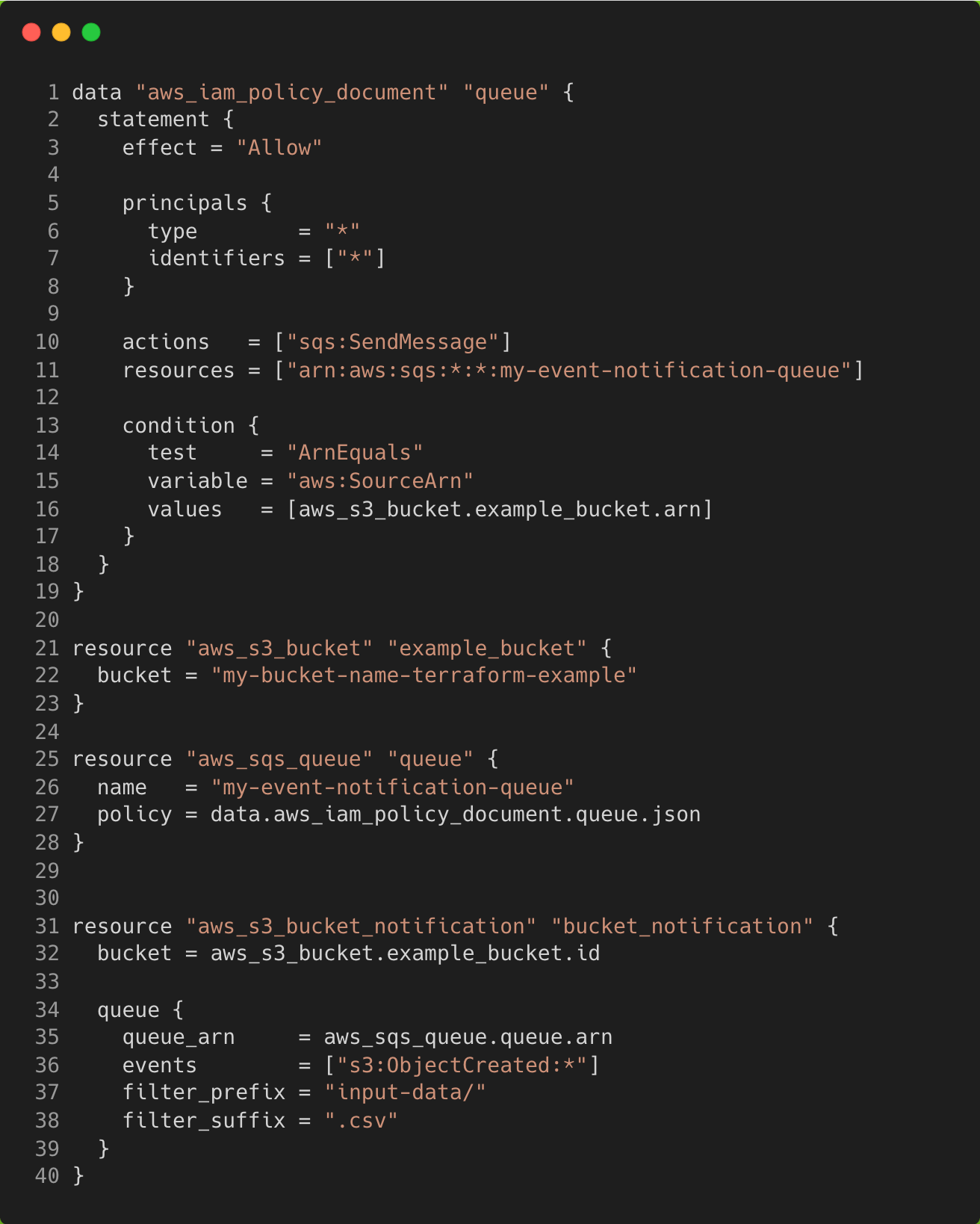
If we want to send messages to a queue instead, we would need to replace the bucket notification contents with a queue, as well as create a policy and role for our queue. The main.tf file should now look like the following
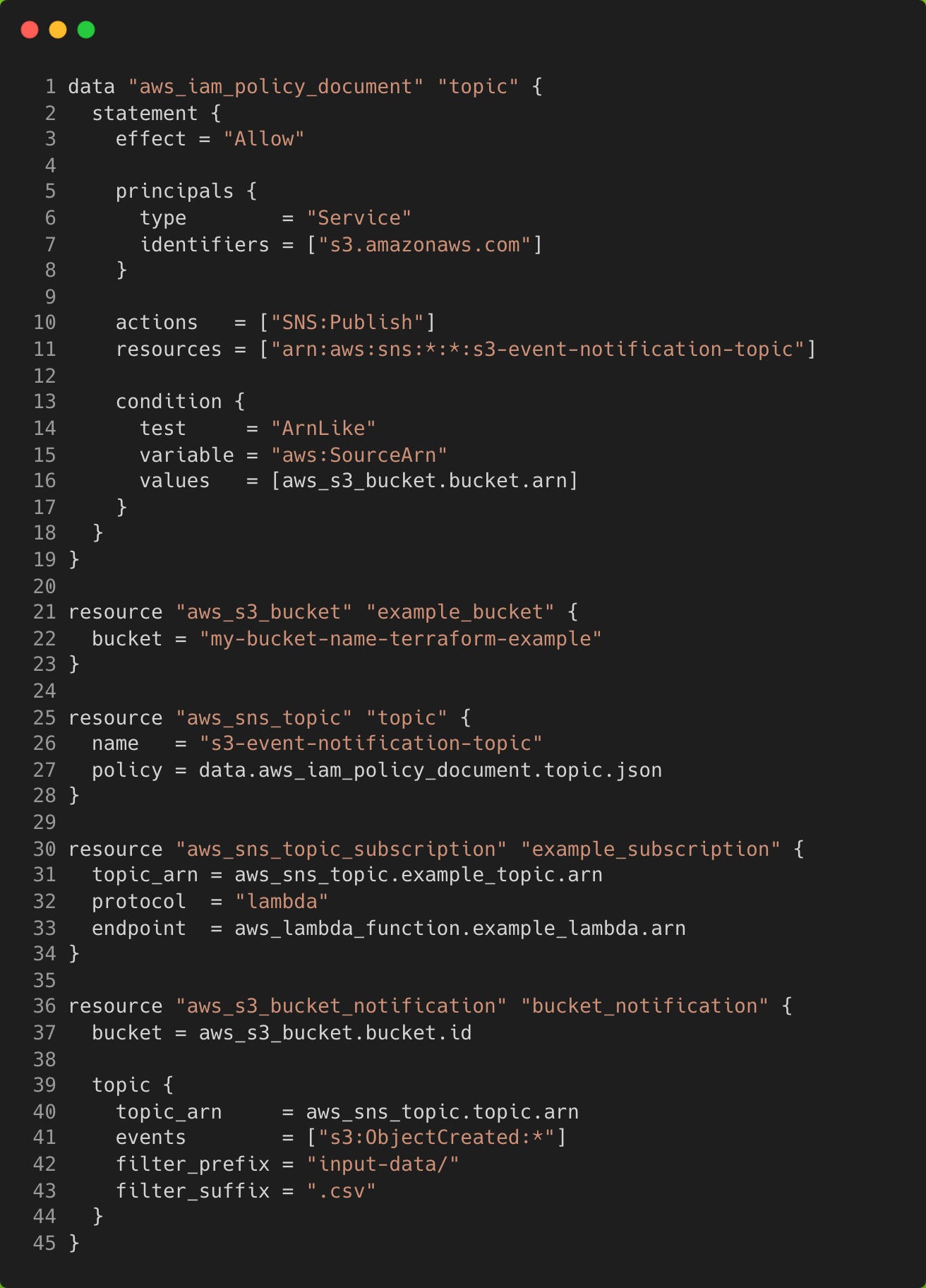
Lastly, we could implement an SNS topic that can publish messages to subscribers of that topic, which will be the Lambda function in this example. The main.tf file should now look like the following
Closing Thoughts
Setting up event-driven pipelines on AWS is fairly simple but can also get complicated depending on the use case. As a data engineer, being able to spin up resources just from your keyboard is an attractive skill to have.
With Terraform, you’ll be able to automate deployments, optimise resources, and scale effortlessly. Embrace it, and become the architect of change in your data engineering journey!