Five Underrated Python Packages For Improving Your Development Experience
For ultimate productivity and the cool factor

👋 Hey Elias here! Today I’m sharing some awesome Python packages I’ve recently used that have made my development experience a little bit better. Thank you for reading and I hope you can take something useful out of this.
Picture yourself immersed in a tricky data engineering task - juggling date manipulations and debugging errors.
Maybe you’re craving a terminal experience that's more than just black and white.
Sound familiar? In this post I’ll briefly cover 5 Python packages that will improve your developing experience and take you to new heights.

1. tqdm
Starting with one of my favourites, tqdm (which actually means “progress” in Arabic and is an abbreviation for “I love you so much” in Spanish) makes visualising your script execution possible via your terminal.
I’ve used it in my previous blog post on concurrency in Python when demonstrating the speed difference between running synchronous and asynchronous API calls using the asyncio implementation of tqdm.
The gif below shows the terminal output when I run the synchronous approach

The output includes information on the number of elements you might be processing in a loop and how long the process took.
This is a nice to have feature if you want simple progress monitoring in your data pipeline scripts to get immediate feedback about the progress of a task.
You can also identify bottlenecks in your scripts by seeing when things slow down with additional logging.
But what if this is not rich enough and you wanted to add some colour to it?
2. Rich
Rich is a very versatile package, giving you the ability to make pretty much anything logged to the console look much better.
It allows you to output rich text with colour and style and similar to tqdm, it also provides a progress bar with colour.
There are plenty of other example use cases on the examples github page you can try to get started with.
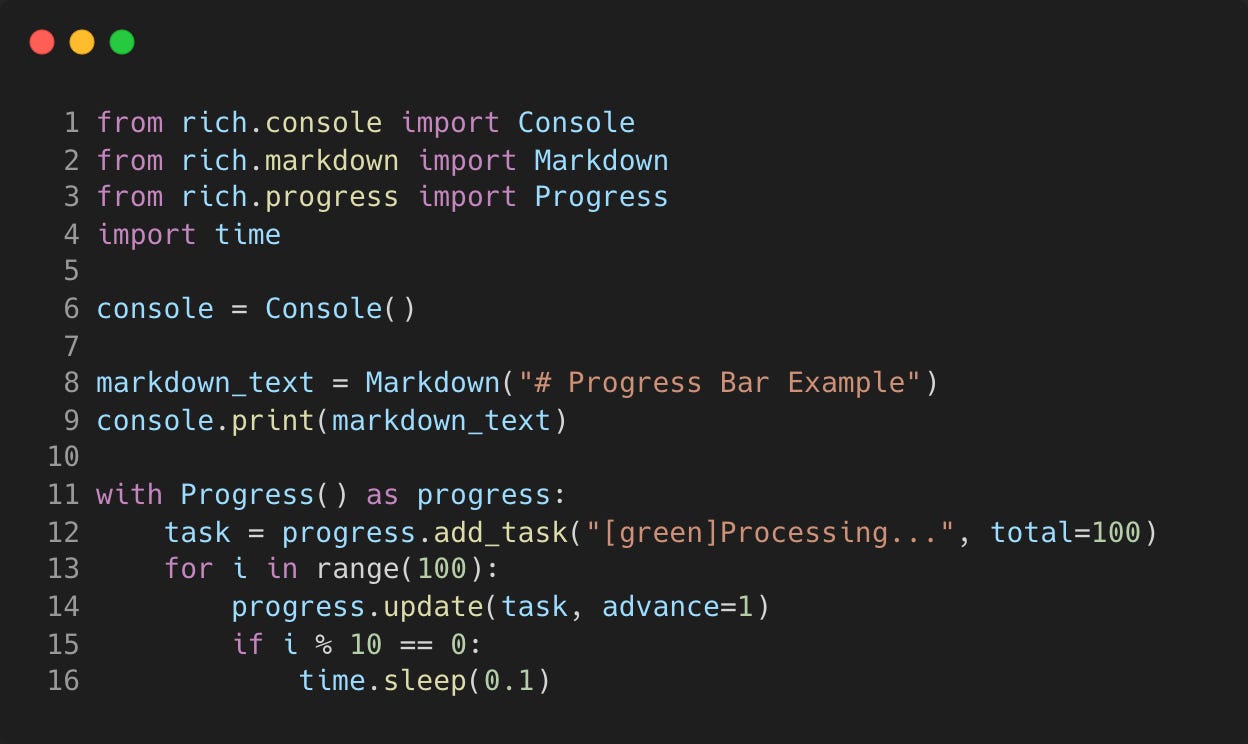
It’s ability to render markdown text with syntax highlighting makes it really easy to style.
In this simple example I create a banner with the heading “Progress Bar Example” with a stylish progress bar.

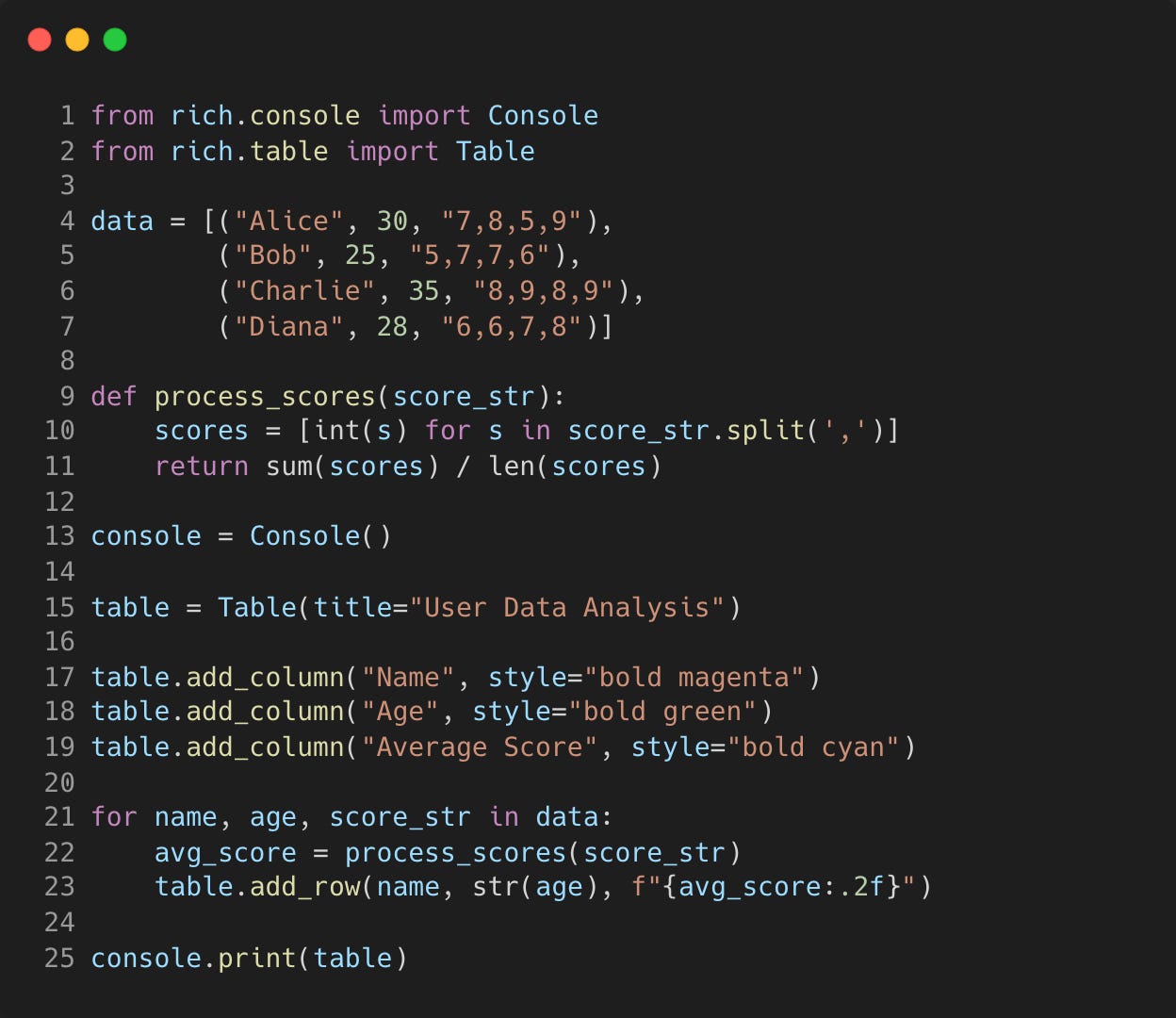
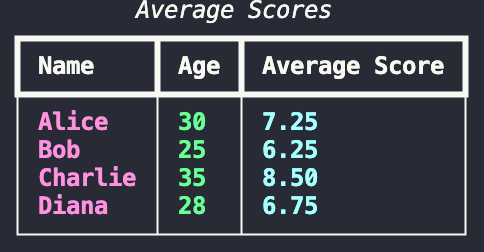
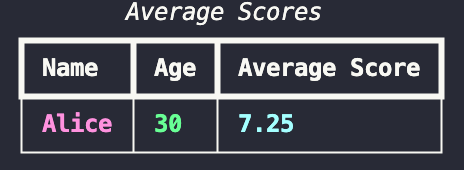
Another useful feature is the printing of tables, which can make your output more readable and informative and is great for quick analysis.
The following code prints out the table below with the header “Average Scores”.
To take it a step further, what if we wanted to dynamically change the output without having to modify the script?
3. Argparse
Provided as part of the standard library, argparse is a powerful tool when building simple command line interfaces.
Taking the code used in the example for Rich, we can add command line argument options which will allow for filtering on the output data.
Here we have added the ability to input the name of each person and/or a minimum average score to filter the results to.
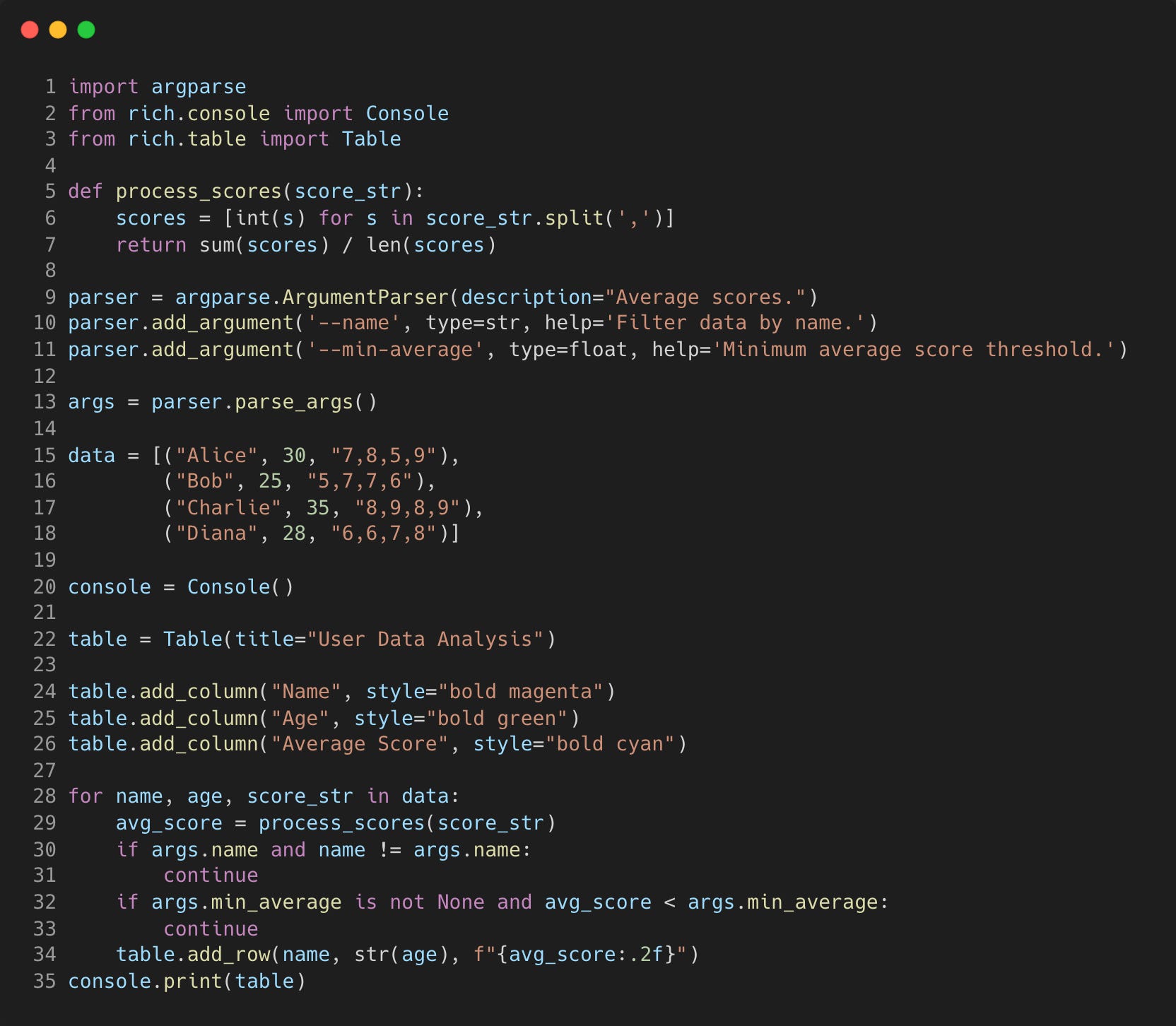
For example, we can filter the results to Alice only and if her average score is greater than 6 by running the script with argument “—name Alice —min-average 6”
If we were to run it with “—name Alice —min-average 9”, we get an empty table as expected

4. Pendulum
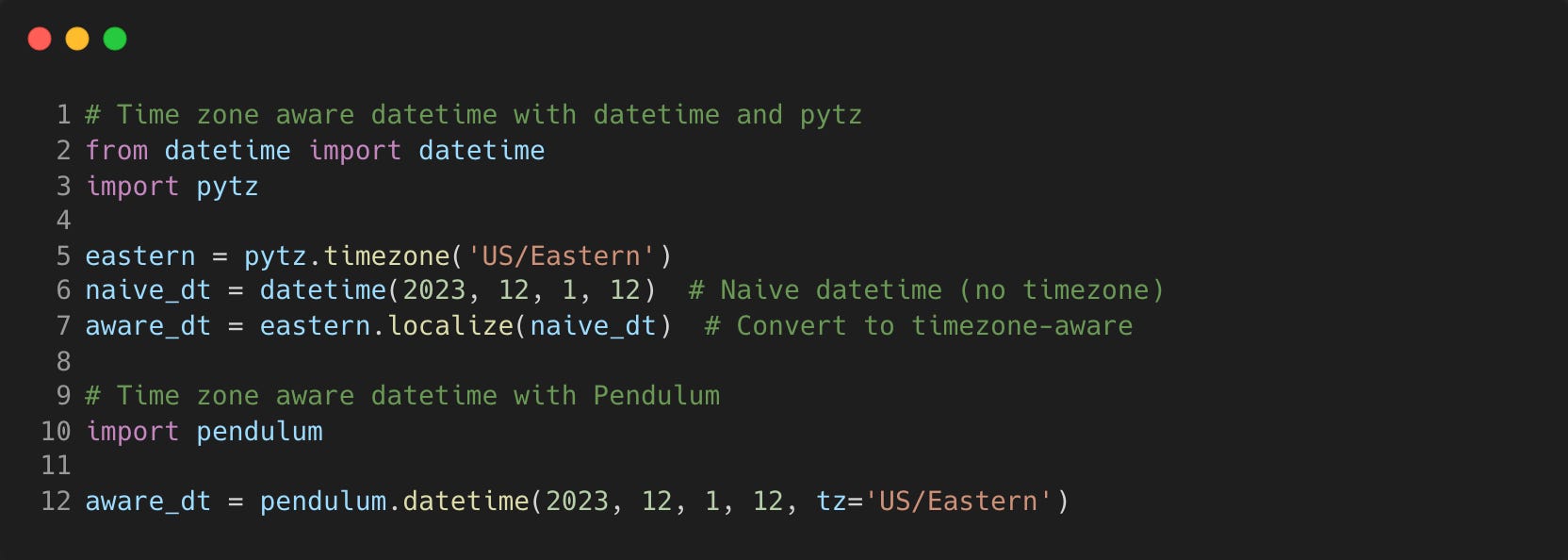
The standard datetime library is very good, but lacks built in time zone support and human readable outputs.
Pendulum provides an easy interface to deal with dates and times, with a more intuitive API.
Datetime objects in Pendulum are immutable, meaning they can’t be changed once created, preventing the chances of unintended side effects.
When processing time-series data, the ease of calculating differences between timestamps, adding/subtracting time intervals, and generating human-readable time differences can simplify many common data engineering tasks.
For example, making timezone aware datetime objects in Pendulum is a breeze compared to using datetime with pytz.
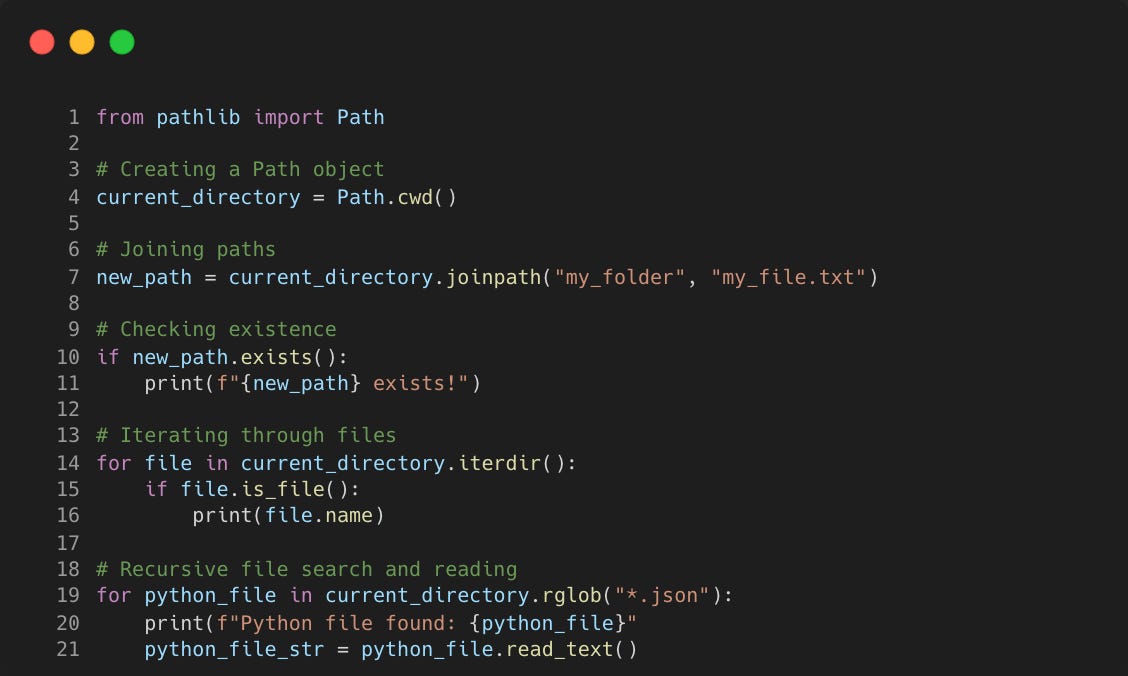
5. Pathlib
Pathlib simplifies the tasks that traditionally required complex string manipulations. It offers a object-oriented and intuitive approach to file operations, treating file and directory paths as first-class citizens.
I really like the clearer syntax and easier readability when iterating over files in a directory. Reading in a text file is more pythonic with the iterdir() command.
There are built in methods to easily check if a directory or file exists (exists()) and wether the path is a directory or file through concise conditional operations (is_dir(), is_file()).
Recursive searches with rglob() makes it easy to search for specific file types throughout a directory tree.